
【LLM】LangChain特性存储和LLM
编者按:非常感谢Willem Pienaar(Feast)、Mike Del Balso(Tecton)和Simba Khadder(FeatureForm)对本文的评论和帮助。
LLM代表了人工智能的一种新范式。有多少对传统机器学习有用的工具和服务在这里仍然相关,这是一个悬而未决的大问题。一方面,对于这种新的范式,有非常真实的新用例和需求。另一方面,现有的工具和服务具有多年的经验、开发和功能强化。这些工具在这个新的范式中仍然有用吗?
特性存储概述
一个特别有趣的案例研究是功能商店。在传统的机器学习中,模型的输入不是原始文本或图像,而是与手头的数据点相关的一系列工程“特征”。特征库是一个特征库,是一个旨在将ML特征集中并提供给模型的系统。通常有两个好处:
一种跟踪在特定时间点存在哪些特征以用于模型训练的方法
- 进行推理时使用的实时特征管道
- 这些可能如何适用于LLM应用程序?
第一点似乎没有那么重要。大多数人使用OpenAI、Anthropic等预先训练的LLM,而不是从头开始训练自己的模型。
【LLM】langchain 和 ChatGTP 4 agents
代理
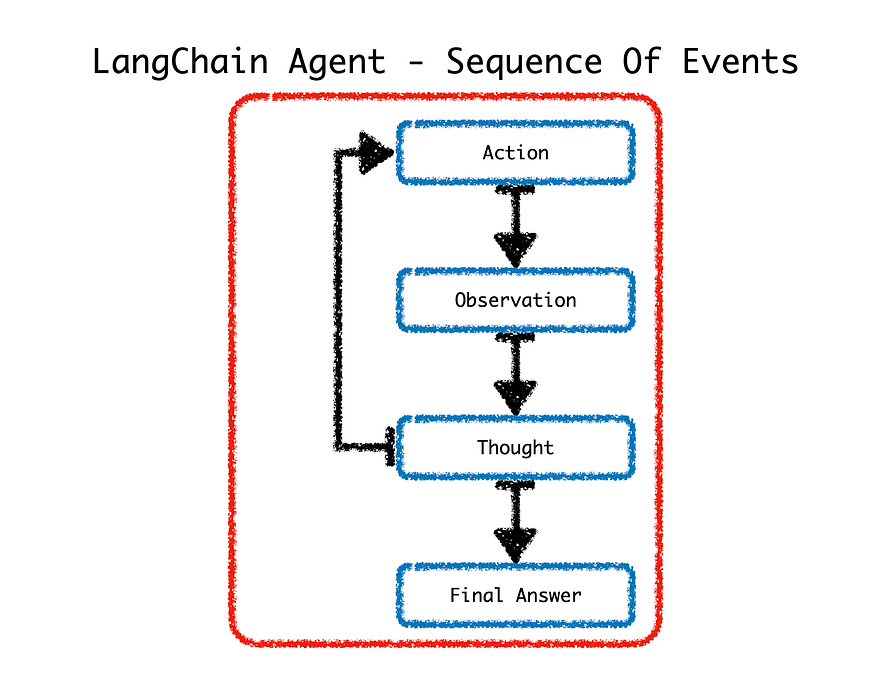
代理通过涉及LLM来确定要遵循的操作序列,从而保持一定程度的自主权。
考虑下图,在收到请求后,代理会利用LLM来决定采取哪种操作。“操作”完成后,Agent将进入“观察”步骤。从观察步骤开始,代理人分享一个想法;如果没有达到最终答案,Agent会循环返回到另一个Action,以便更接近最终答案。
LangChain代理可以使用一系列操作。
下面的代码显示了LangChain代理回答一个极其模糊和复杂的问题的完整工作示例:
Who is regarded as the father of the iPhone and what is the square root of his year of birth?
代理人可以采取一些行动:
LLM数学,
以下是SerpApi网站的截图。SerpApi使得从搜索引擎结果中提取数据变得可行。
GPT-4(GPT-4–0314)。
【ChatGTP】使用ChatGPT探索数据建模:第1部分:ChatGPT手动实验

数据建模主要由人类专家进行,包括拥有专业知识和技能的数据架构师、数据建模者和分析师。然而,人工智能的最新进展,特别是在自然语言处理(NLP)和大型语言模型(LLM)方面,引发了人们对其对该领域潜在影响的讨论。作为一名数据爱好者,这让我思考我能在多大程度上突破这些新的人工智能功能的界限,尤其是使用ChatGPT。我决定进行一系列实验来探索各种可能性。
在我实验的最初阶段,我的重点将是手动执行任务和流程,而不是依赖自动化。通过采用这种实践方法,我的目标是全面了解与主题相关的概念、方法和挑战。此外,它将使我能够收集有价值的见解和反馈,这些见解和反馈可以指导未来关于自动化的决策。通过这项手动工作,我的目标是获得可用于评估集成自动化的实用性和优势的知识和经验。
如果你是数据建模领域的新手,我邀请你阅读我关于数据建模在人工智能时代的重要性的另一篇文章。你可以在以下链接找到:数据建模在AI时代的重要性
入门:
获取ChatGPT登录。
【ChatGTP】驯服魔鬼:使用ChatGPT简化软件开发
纵观历史,魔鬼和恶魔的故事一直是民间传说和神话的主要内容。狡猾的巫师驯服这些强大的生物来执行他们的命令的故事吸引了几代观众。
让我们从一个关于狡猾的魔鬼和聪明的巫师的简短故事开始。
从前,在两座高耸的山脉之间的一个小村庄里,住着一位名叫阿拉里克的聪明的老巫师。在一个决定性的日子里,阿拉里克的任务是制造一种药水,可以治愈肆虐附近土地的可怕瘟疫。然而,关键成分,一种罕见的金色草本植物,只能在闹鬼的森林中找到。
阿拉里克为了拯救他的人民,不顾一切地召唤了一个狡猾的魔鬼泽菲罗斯,并达成了协议。作为Zephyros在危险的森林中航行和取回金色草药的帮助的交换,巫师承诺将魔鬼从一个世纪的奴役中释放出来。凭借魔鬼的指引和无与伦比的敏捷,阿拉里克冒着森林中的重重陷阱和危险,最终获得了难以捉摸的金色草药。
他们一起回到了村庄,阿拉里克在那里成功地酿造了救命药,结束了这场毁灭性的瘟疫。巫师信守诺言,将泽菲罗斯从束缚中释放出来,魔鬼和巫师对彼此的能力和决心都获得了新的尊重。
这个故事的寓意强调了相互尊重和合作的重要性。虽然魔鬼拥有独特的能力,但它需要我们的帮助才能完成任务。通过共同努力,我们可以更有效地实现我们的目标。
【ChatGPT 】如何使用自定义知识库构建自己的自定义ChatGPT
ChatGPT已经成为大多数人每天用来自动化各种任务的不可或缺的工具。如果你使用过ChatGPT任何一段时间,你都会意识到它可能会提供错误的答案,并且在一些小众主题上限制为零上下文。这就提出了一个问题,即我们如何利用chatGPT来弥合差距,并允许chatGPT拥有更多的自定义数据。
丰富的知识分布在我们日常互动的各种平台上,即通过工作中的融合wiki页面、松弛组、公司知识库、Reddit、Stack Overflow、书籍、时事通讯和同事共享的谷歌文档。掌握所有这些信息来源本身就是一项全职工作。
如果你能有选择地选择你的数据源,并将这些信息轻松地输入到ChatGPT与你的数据的对话中,那不是很好吗?
1.通过Prompt Engineering提供数据
在我们讨论如何扩展ChatGPT之前,让我们看看如何手动扩展ChatGPT以及存在哪些问题。扩展ChatGPT的传统方法是通过即时工程(prompt engineering)。
这很简单,因为ChatGPT是上下文感知的。首先,我们需要通过在实际问题之前附加原始文档内容来与ChatGPT进行交互。
【ChatGPT 】如何使用自己的数据创建私人ChatGPT
了解使用ChatGPT/LLM创建自己的问答引擎所需的体系结构和数据要求。
【ChatGTP】斯坦福大学的Alpaca人工智能是什么?计算机科学家以不到600美元的价格创建的类似ChatGPT的模型
Alpaca是一个基于Meta的LLaMA系统的小型人工智能语言模型。出于安全和成本考虑,斯坦福大学的研究人员最近从互联网上删除了该演示。
大型语言模型包含数百亿或数百亿个参数,它们的访问通常仅限于有足够资源来训练和运行这些人工智能的公司。
快速增长的Meta决定与一些精选的研究人员分享其著名的LLaMA系统的代码。该公司希望找出语言模型产生有毒和虚假文本的原因。他们希望它能在研究人员不需要大规模硬件系统的情况下发挥作用。
于是,羊驼出生了。斯坦福大学的一组计算机科学家将LLaMA微调为一个名为Alpaca的新版本。这个新版本是一个开源的70亿参数模型。根据《新地图集》,它的建造成本不到600美元。
Alpaca已经调整了50000多个文本样本,使其信息更加准确
Alpaca的代码向公众发布,引起了几位开发人员的注意。他们成功地在树莓派电脑和Pixel 6智能手机上启动并运行了它。
斯坦福德的研究人员谈到了包括GPT-3.5、ChatGPT、Claude和Bing Chat在内的“指令遵循模型”是如何变得“越来越强大”的。该研究所的网站上写道: