
【LLM】大型语言模型综述
【LLM】Free Dolly:推出世界上第一个真正开放的指令调谐LLM
两周前,我们发布了Dolly,这是一个大型语言模型(LLM),经过不到30美元的训练,可以展示类似ChatGPT的人机交互(又称指令跟随)。今天,我们将发布Dolly 2.0,这是第一个开源的指令遵循LLM,它对授权用于研究和商业用途的人工生成指令数据集进行了微调。
Dolly 2.0是一个基于EleutherAI pythia模型家族的12B参数语言模型,专门针对Databricks员工众包的新的、高质量的人工生成指令跟踪数据集进行了微调。
我们正在开源Dolly 2.0的全部内容,包括训练代码、数据集和模型权重,所有这些都适合商业使用。这意味着任何组织都可以创建、拥有和定制功能强大的LLM,这些LLM可以与人对话,而无需为API访问或与第三方共享数据付费。
【LLM】自主GPT-4:从ChatGPT到AutoGPT、AgentGPT、BabyAGI、HuggingGPT等
LangChain和LlamaIndex集成趋势后,GPT-4的新兴任务自动化和人工智能代理
ChatGPT和LLM技术的出现是革命性的。这些最先进的语言模型席卷了世界,激励开发人员、爱好者和组织探索集成和构建这些尖端模型的创新方法。因此,LangChain和LlamaIndex等平台如雨后春笋般涌现,以简化集成并促进新应用程序的开发。
随着我们继续集成ChatGPT和LLM,我们看到越来越多的自主任务和代理利用GPT-4的功能。这些发展不仅增强了处理集成不同系统的复杂任务的能力,还突破了我们使用自主人工智能所能实现的极限。
在Jupyter笔记本中使用Python语言链在Mac上运行GPT4All
在过去的三周左右时间里,我一直在关注本地运行的大型语言模型(LLM)的疯狂开发速度,从llama.cpp开始,然后是alpaca,最近是(?!)gpt4all。
在那段时间里,我的笔记本电脑(2015年年中的Macbook Pro,16GB)在修理厂里呆了一个多星期,直到现在我才真正有了一个快速的游戏机会,尽管我10天前就知道我想尝试什么样的东西,而这在过去几天才真正成为可能。
根据这个要点,以下脚本可以作为Jupyter笔记本下载 this gist.
【langchain】在单个文档知识源的上下文中使用langchain对GPT4All运行查询
In the previous post, Running GPT4All On a Mac Using Python langchain in a Jupyter Notebook, 我发布了一个简单的演练,让GPT4All使用langchain在2015年年中的16GB Macbook Pro上本地运行。在这篇文章中,我将提供一个简单的食谱,展示我们如何运行一个查询,该查询通过从单个基于文档的已知源检索的上下文进行扩展。
I’ve updated the previously shared notebook here to include the following…
基于文档的知识源支持的示例查询
使用langchain文档中的示例进行示例文档查询。
【ChatGPT】提示设计的艺术:使用清晰的语法
探索清晰的语法如何使您能够将意图传达给语言模型,并帮助确保输出易于解析

这是与Marco Tulio Ribeiro共同撰写的关于如何使用指导来控制大型语言模型(LLM)的系列文章的第一部分。我们将从基础知识开始,逐步深入到更高级的主题。
在这篇文章中,我们将展示清楚的语法使您能够向LLM传达您的意图,并确保输出易于解析(如保证有效的JSON)。为了清晰和再现性,我们将从开源的StableLM模型开始,无需微调。然后,我们将展示相同的想法如何应用于像ChatGPT/GPT-4这样的微调模型。下面的所有代码都可以放在笔记本上,如果你愿意的话可以复制。
【LLM】LangChain 资料大全
【LLM】LangChian自动评估( Auto-Evaluator )机会
编者按:这是兰斯·马丁的一篇客座博客文章。
TL;DR
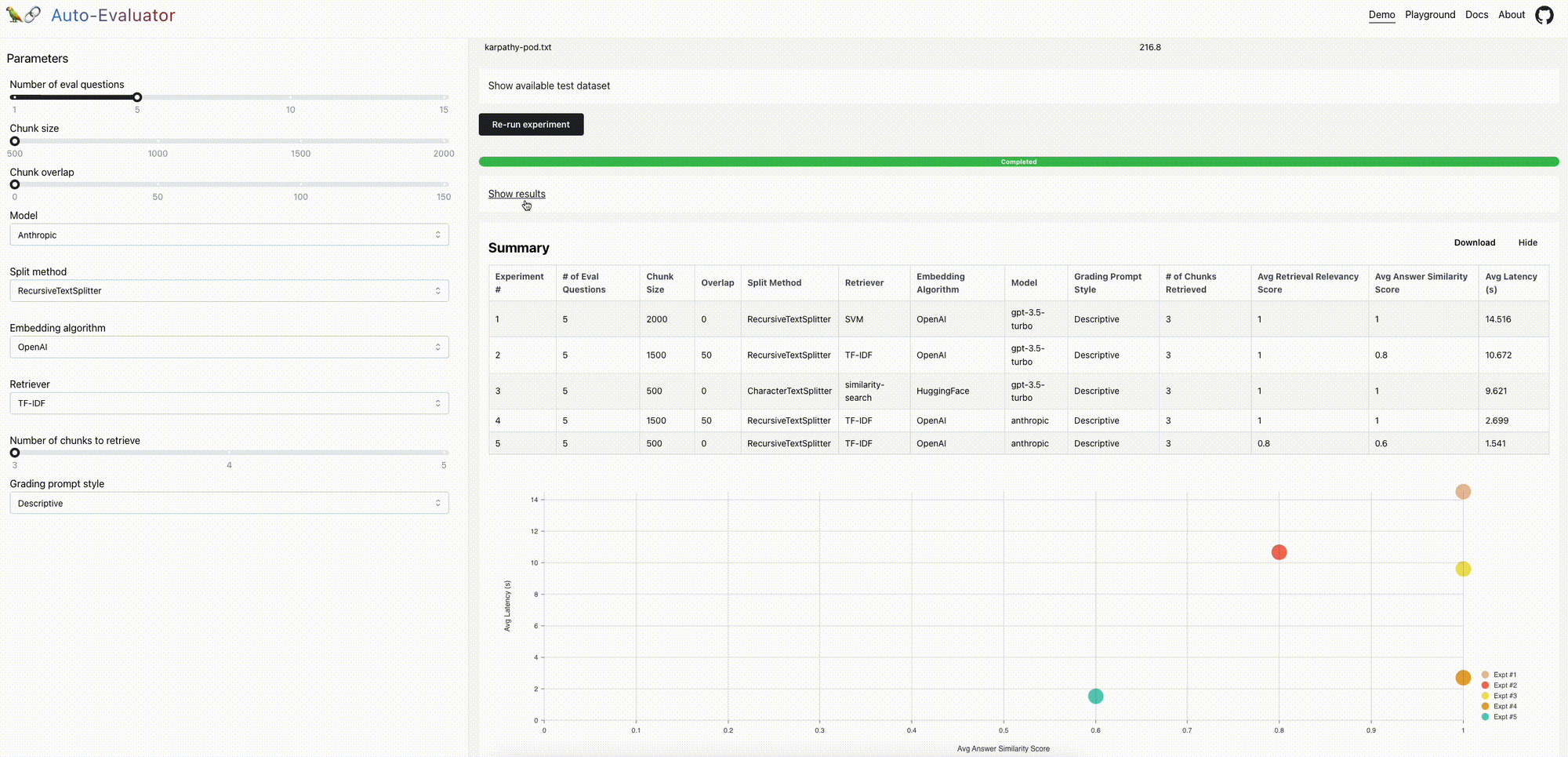
我们最近开源了一个自动评估工具,用于对LLM问答链进行评分。我们现在发布了一个开源、免费的托管应用程序和API,以扩展可用性。下面我们将讨论一些进一步改进的机会。
上下文
文档问答是一个流行的LLM用例。LangChain可以轻松地将LLM组件(例如,模型和检索器)组装成支持问答的链:输入文档被分割成块并存储在检索器中,在给定用户问题的情况下检索相关块并传递给LLM以合成答案。
问题
质量保证系统的质量可能有很大差异;我们已经看到由于特定的参数设置而产生幻觉和回答质量差的情况。但是,(1)评估答案质量和(2)使用此评估来指导改进的QA链设置(例如,块大小、检索到的文档数)或组件(例如,模型或检索器选择)并不总是显而易见的。
【LangChain 】LangChain 计划和执行代理
TL;DR:我们正在引入一种新型的代理执行器,我们称之为“计划和执行”。这是为了与我们以前支持的代理类型形成对比,我们称之为“Action”代理。计划和执行代理在很大程度上受到了BabyAGI和最近的计划和解决论文的启发。我们认为Plan and Execute非常适合更复杂的长期规划,但代价是需要调用更多的语言模型。我们正在将其初始版本放入实验模块,因为我们预计会有快速的变化。
链接:
到目前为止,LangChain中的所有代理都遵循ReAct文件开创的框架。让我们称之为“行动特工”。这些算法可以大致用以下伪代码表示:
【LLM】LangChain 的Callbacks 改进
TL;DR:我们宣布对我们的回调系统进行改进,该系统支持日志记录、跟踪、流输出和一些很棒的第三方集成。这将更好地支持具有独立回调的并发运行,跟踪深度嵌套的LangChain组件树,以及范围为单个请求的回调处理程序(这对于在服务器上部署LangChain非常有用)。