
category
20240215 Additional content: Unveiling PDF Parsing: How to extract formulas from scientific pdf papers
20240316: This article focuses on tables: Advanced RAG 07: Exploring RAG for Tables
For RAG, the extraction of information from documents is an inevitable scenario. Ensuring the effectiveness of content extraction from the source is crucial in improving the quality of the final output.
It is important not to underestimate this process. When implementing RAG, poor information extraction during the parsing process can lead to limited understanding and utilization of the information contained in PDF files.
The position of the Pasing process in RAG is shown in Figure 1:
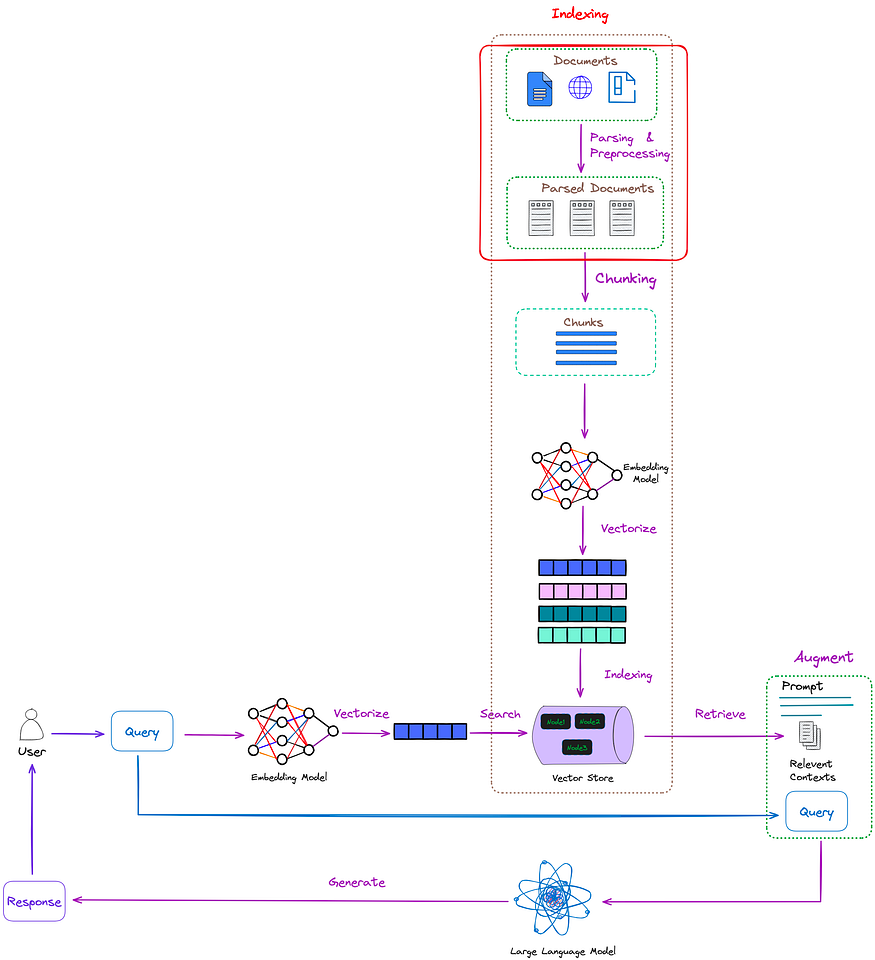
In practical work, unstructured data is much more abundant than structured data. If these massive amounts of data cannot be parsed, their tremendous value will not be realized.
In unstructured data, PDF documents account for the majority. Effectively handling PDF documents can also greatly assist in managing other types of unstructured documents.
This article primarily introduces methods for parsing PDF files. It provides algorithms and suggestions for effectively parsing…
- 登录 发表评论