
category
通过RAG致富:利用LLM的力量,使用检索增强生成与您的数据对话
问ChatGPT一个关于“马拉松”一词起源的问题,它会准确地告诉你希罗多德是如何描述费迪皮德斯从马拉松到雅典完成的42公里传奇长跑的,然后筋疲力尽。
但我祖母的食谱清单呢?当然,我可以把这些食谱数字化,没问题。但是,如果我想根据冰箱里的食材、我最喜欢的颜色和我一天的心情,就准备哪顿饭提出建议,该怎么办?
让我们看看这是否有可能在不因精疲力竭而崩溃的情况下实现。
LLM,达到你的极限…并超越它们
LLM是一种大型语言模型。OpenAI的GPT-4是一个例子,Meta的LLamA是另一个例子。我们在这里有意识地选择使用一般LLM术语来指代这些模型。请记住:这些模型中的每一个都是在一组庞大的(公开可用的)数据上进行训练的。
到目前为止,已经清楚地表明,这些LLM对通用语言有着有意义的理解,并且他们能够(重新)产生与训练数据中存在的信息相关的信息。这就是为什么像ChatGPT这样的生成工具在回答LLM在培训过程中遇到的主题问题方面表现惊人。
但是,这些庞大的LLM仍然无法直接掌握的是每个组织内部非常有价值的数据:内部知识库。由此大量出现的问题是:
我们如何利用这些LLM的力量来解锁存储在特定知识库中的信息,而这些知识库最初并不是基于这些知识库进行训练的?
哦,好吧,所以要做到这一点,我们就不能把我们的内部知识库作为LLM应该训练的额外数据来介绍吗?或者,如果你愿意的话,我们可以根据我们的特定知识库对LLM进行微调吗。
是的,你很可能会。但对于可靠的问题回答来说,这可能不是一条路。
为什么微调不会总是削减成本
认识书虫比利。Billy是一个大型语言模特,他吞噬了大量的在线信息,拥有丰富的知识。然而,尽管Bily很聪明,但他并没有把你家图书馆里的书通读一遍。
微调是这样的:向书虫比利展示你特定知识库中的所有书籍,让他狼吞虎咽地阅读所有美味的额外信息。这样,LLM书虫Billy不仅知道所有的一般信息,他还“知道”了很多关于你特定知识库的内容。
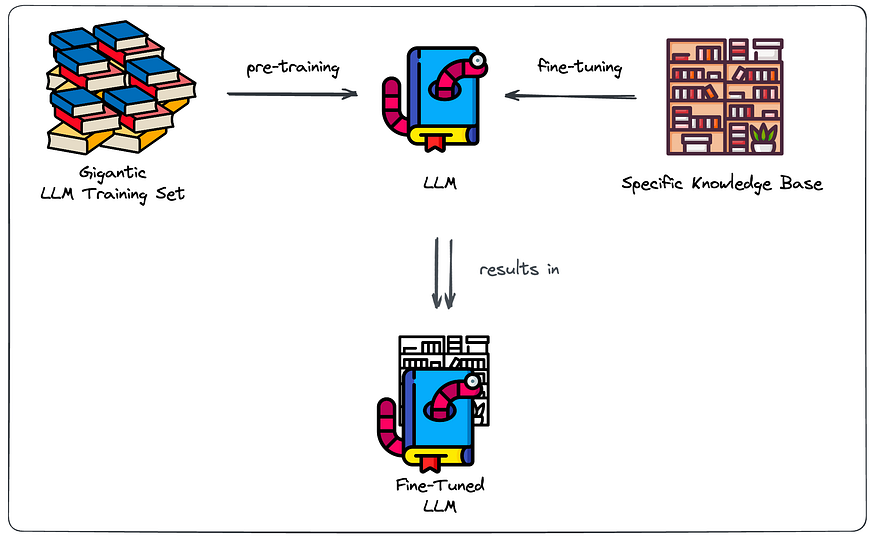
Classical approach of fine-tuning on domain specific data (all icons from flaticon)
祝贺你,通过这个微调过程,你已经把Billy变成了一个非常具体的Billy,他对你的特定领域非常了解!下面我们将展示如何让Billy开始工作。通过向改进后的书虫提出问题,您可以期待使用其庞大的通用训练集中的信息和存储在特定知识库中的信息的答案。
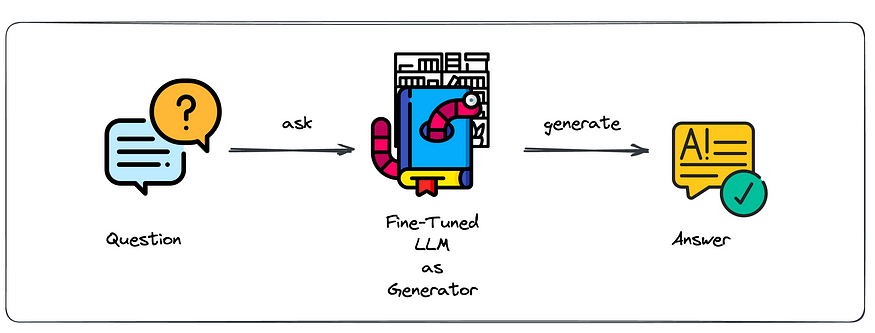
Leveraging the fine-tuned LLM to ask questions about your internal knowledge base.
虽然这种解决方案确实很强大,但关键的问题是,你对你的书虫是如何找到答案的仍然知之甚少。此外,对LLM进行微调也会带来(代价高昂的)后果。
我们列出了微调Billy失败的主要原因:
- 没有明确的来源。很难预防幻觉,你的LLM对“一般”和“特定”知识没有明确的区分。
- 无访问限制。想象一下这样一种情况:一些用户应该能够查询战略文档的信息,而另一些用户则不应该。你将如何解决这个问题?你微调过的比利什么都知道,他不能选择在推理时遗漏知识。
- 托管LLM成本高昂。一旦你有了一个微调的LLM,你就必须让它继续旋转。一个大的语言模型很好…很大。维持和运行的成本将会增加。收益是否大于成本?
- 微调重复。当您希望模型反映知识库的更改时,需要对模型进行再培训。
幸运的是,所有这些问题都是可以解决的。如果你想要的是以可验证的方式回答问题并防止幻觉:你可能不需要超现代的书虫,让我们问问优秀的老图书管理员在哪里可以找到你问题的答案。
有RAG到Riches
检索增强生成(RAG)背后的想法是非常直接的。记住,我们的目标是解锁我们知识库中的信息。我们没有在上面释放(即微调)我们的书虫,而是全面索引我们的知识库信息。

By indexing the embeddings of your internal knowledge base, you unlock smart search capabilities.
在上面的模式中,我们展示了智能检索器如何像图书管理员一样工作。理想情况下,图书管理员对图书馆里的东西有完全的了解。对于一个问某个问题的访客,他会知道该推荐哪本书的哪一章。
在更技术的层面上,这描述了一个语义搜索引擎。在这种情况下,嵌入是文档部分的矢量表示,并且它们允许对存储在每个部分中的实际含义进行数学描述。通过比较嵌入,我们可以确定哪些文本部分在意义上与其他哪些文本部分相似。这对于下面显示的检索过程至关重要。
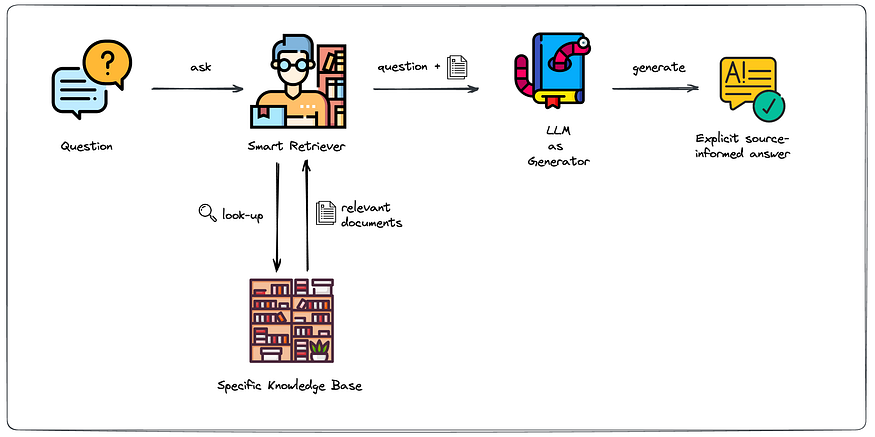
Through leveraging our Smart Retriever, we can force our generator to stick to the content of our knowledge base that is most relevant for answering the question. Et voilà: Retrieval-Augmented Generation.
其中有两个关键组成部分:
- 智能寻回器(即图书管理员)
- 生成器(即书虫)
现在应该很清楚为什么这种方法被称为检索增强生成。根据所问的问题,您首先从您的内部知识库中检索最相关的信息;然后,通过将相关信息明确地传递给生成器组件来增强典型的生成阶段。
这种基于RAG的设置的关键亮点
- 明确指出答案所依据的来源。允许验证生成器返回的答案。
- 不太可能产生幻觉,通过将我们的生成器组件限制在我们的知识库语料库中,它会承认,当检索器没有找到相关来源时,它无法形成响应。
- 可维护搜索索引。知识库是一个有生命的东西,当它发生变化时,我们可以调整我们的搜索索引来反映这些变化。
除了这些亮点之外,LLM的多语言方面也是一件很美的事情。你可以有一个由纯意大利食谱组成的知识库,你喜欢意大利面的法国朋友可以在全法语对话中与之交谈。
重新进行微调
请注意,在上一节中,我们认为微调是一个有价值的选择,因为我们几乎无法控制源的清晰度,从而增加了产生幻觉的风险。
必须注意的是,由通用LLM提供支持的RAG方法只有在特定知识库不包含LLM无法从其一般培训中理解的超特定术语的情况下才能很好地工作。
想象一下,你需要你的解决方案的回应来遵循你知识库中的“语气和行话”。在这种情况下,LLM的微调似乎不那么可以避免。
这可能是一种有效的方法,能够处理特定的行话,然后将您经过微调的LLM纳入RAG架构中,以获得综合优势。然后,您将使用经过专门训练的Billy为发电机和/或智能寻回器组件供电,而不是使用普通的书虫。
为什么是现在?有什么新鲜事吗?
很好的问题。
语义搜索(智能检索)已经存在了很长一段时间,生成人工智能也已经存在了(一些原始形式已经存在了几十年)。
然而,在过去几个月里,我们看到了关键性的进展。
在技术层面上,我们最近见证了LLM性能的巨大飞跃。这些在两个层面上对RAG解决方案产生了积极影响:
- 嵌入(例如OpenAI或Google的PaLM嵌入API)
- 生成功能(例如OpenAI的ChatGPT解决方案)
伴随着生成质量的提高,牵引力也随之增加。以前,公司无法轻易想象依赖生成人工智能的系统的机会。然而,现在,由于媒体的广泛报道和ChatGPT等工具的采用,整体兴趣呈指数级增长。
因此,尽管可以说RAG的平庸版本在相当长的一段时间内是可能的,但技术的改进和吸引力的增加带来了富有成效的市场机会。
成功路上的挑战
在本节中,我们旨在向您介绍建立成功的RAG解决方案所面临的一些主要挑战。
对智能检索器性能的依赖性很强。
生成组件提供的响应的质量将直接取决于智能检索器提供给它的信息的相关性。如上所述,我们可以感谢LLM的进步为我们提供了丰富而强大的文本嵌入。但纯粹通过API获取这些嵌入可能不是您的最佳选择。在设计语义搜索组件时,你应该非常小心,也许你的知识库有特定的行话,你可能需要一个定制的(即微调的)组件来处理它。关于语义搜索的更深入的实用指南可以在这篇博客文章中找到[1]。
为了坚持知识库中的信息,需要在限制中进行权衡。
正如RAG体系结构中所解释的那样,我们可以强制LLM生成组件将自己限制在相关文档中的信息中。虽然这确保了幻觉(即无意义的答案)几乎没有机会,但这也意味着你几乎没有利用你的LLM所拥有的信息。您可能希望您的解决方案也使用这些知识,但可能只有在用户要求时才使用。
对话式设计,允许进行复杂的对话。
虽然我们上面的描述将用户行为表示为只问一个“一次性问题”,但您的用户通常可能想放大您的解决方案提供的答案(在ChatGPT风格的对话中)。幸运的是,有工具可以在这场战斗中帮助你。langchain框架为实现这一点提供了帮助。
提示工程是引导一代人走向成功的一种方式。
为了得到生成组件的正确答案,您需要告诉它您期望的输出类型。总的来说,这与火箭科学相去甚远。但是,使您的提示设置恰好适合您的用例需要时间,并且值得足够的关注。查看提示管理系统可能是值得的,以确保您能够跟踪哪种提示最适合哪种情况。
选择正确的LLM:它的成本是多少?我的数据去了哪里?
在本文中,我们没有明确选择在您的解决方案中使用什么LLM。在选择使用哪种LLM(API)时,请确保考虑隐私和成本限制。已经有相当不错的选择了。我们有OpenAI的GPT、Meta的LLaMA、谷歌的PaLM,埃隆·马斯克声称要加入LLM,谁知道事情会走向何方。令人兴奋的消息是:将会有更多的选择,竞争应该会推动LLM的业绩上升和价格下降。
获取并保持您的LLM解决方案在生产中(LLMOps)。
与所有成熟的人工智能解决方案一样:构建它们是一回事,让它们投入生产是另一回事。LLMOps领域专注于LLM的操作。监控基于LLM的解决方案的性能,使您的知识库和搜索索引保持最新,处理会话历史…
在将LLM解决方案投入生产之前,明智地思考如何维护它,以及如何从长远来看保持它的成效。
被RAG的潜力所吸引,并对相关挑战感兴趣,我们现在开始研究一个基于RAG的实际解决方案。
用RAG弄脏你的手
如果你的兴趣是由检索增强一代的概念激发的,你可能会问自己:
我有能力使用基于RAG的解决方案进行旋转吗?
好吧,如果你有:
- 特定知识:一个适度(最好有组织)的“知识文章”数据库,其中包含在万维网上不易找到的有用信息(如技术文件、入职指南、处理过的支持票…)
- 商业价值:如果信息可以为预期用户解锁,那么商业价值的明确定义
那么,是的,RAG可能是你的选择。
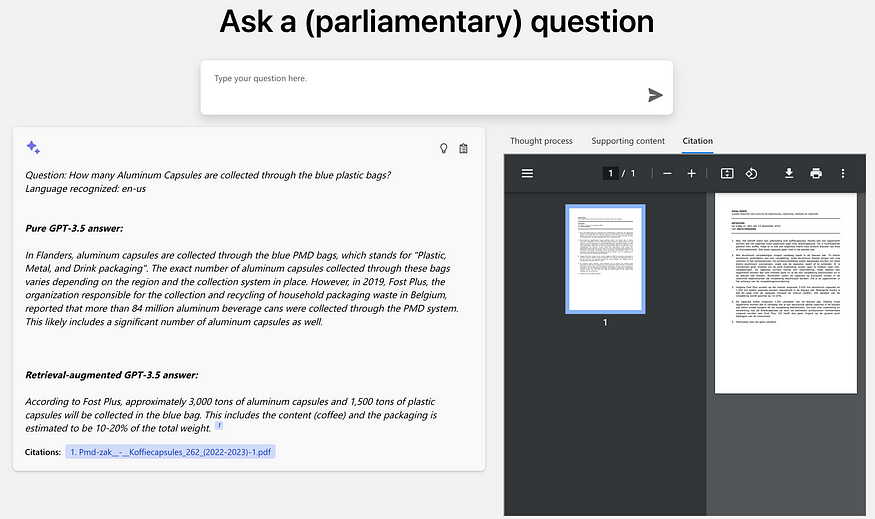
作为一项实验,我们最近制作了一个小型演示,展示如何利用这项技术来支持政府工作人员更容易地回答议会问题。
在这种情况下,具体知识包括:
- 一套佛兰德立法文件
- 过去的一系列议会问题
与此同时,业务价值在于:
- 通过根据佛兰德知识库自动提出议会问题的答案来提高效率
- 通过明确引用提高透明度和用户采用率
如果您正在寻找一些关于如何在技术上实现类似解决方案的指导方针,请继续关注后续的博客文章,我们的目标是放大设置RAG的技术细节。
工具书类
- Mathias Leys (May 9, 2022) Semantic search: a practical overview https://blog.ml6.eu/semantic-search-a-practical-overview-bf2515e7be76
- 登录 发表评论