
这篇博文是对 justforfunc 第 28 集的补充,您可以在下方观看。
https://youtu.be/2AulMm-hsdI
在上一篇博文中,我讨论了在 Go 中合并 n 个通道的两种不同方式,但我们没有讨论哪种方式更快。与此同时,YouTube 评论中提出了第三种合并频道的方法。
这篇博文将展示第三种方式,并从性能角度比较所有方式,并使用基准进行分析。
第三种渠道合并方式
两集前,我们讨论了如何使用单个 goroutine 和 nil 通道合并两个通道。我们将这里的该函数称为 mergeTwo。一个 justforfunc 查看器提出了一种使用此函数和递归的方法,以提供一种合并 n 个通道的方法。
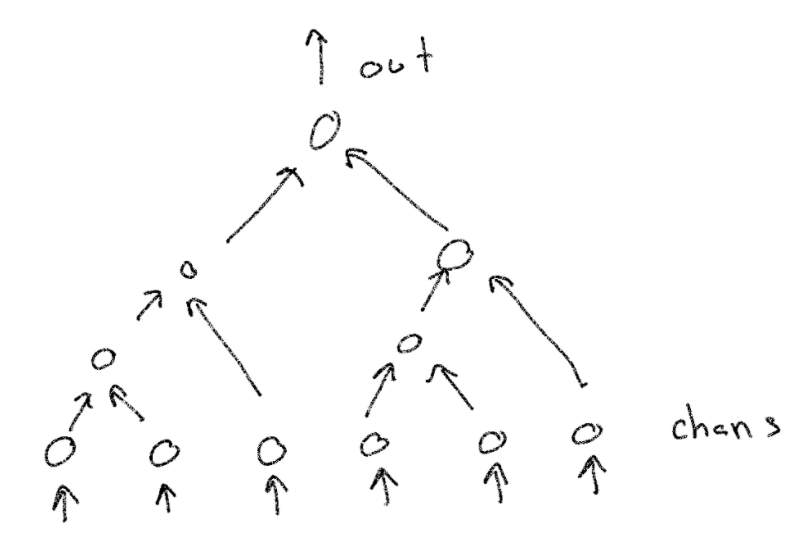
使用递归合并 N 个通道
解决方案非常聪明。如果我们有:
- 一个频道,我们返回那个频道。
- 两个或更多通道,我们合并一半通道,然后使用使用高效函数的结果合并它们。
没有频道怎么办?我们将返回一个已经关闭的通道。
写在代码中,它看起来像这样:
func mergeRec(chans ...<-chan int) <-chan int {
switch len(chans) {
case 0:
c := make(chan int)
close(c)
return c
case 1:
return chans[0]
default:
m := len(chans) / 2
return mergeTwo(
mergeRec(chans[:m]...),
mergeRec(chans[m:]...))
}
}
注意:mergeTwo 在这里定义
这是一个很好的解决方案,可以避免使用反射,还可以减少所需的 goroutine 数量。另一方面,它使用了比以前更多的渠道!
那么,哪一个最快?基准测试的时间!
编写基准
测试和基准测试与 Go 工具非常紧密地集成在一起,编写基准测试就像编写一个名称以 Benchmark 开头和适当签名的函数一样简单。
基准测试接收的唯一参数是类型 testing.B,它定义了我们应该执行基准测试操作的次数。这是为了统计意义而完成的,默认情况下,基准测试会进行多次迭代,这将使函数运行一整秒。
func BenchmarkFoo(b *testing.B) {
for i := 0; i < b.N; i++ {
// perform the operation we're analyzing
}
}
好的,所以现在我们几乎知道了为我们的一个函数编写基准测试所需知道的一切。
对我们所有的功能进行基准测试
好的,所以我们已经准备好为每个函数编写基准了!
一个用于合并:
func BenchmarkMerge(b *testing.B) {
for i := 0; i < b.N; i++ {
c := merge(asChan(0, 1, 2, 3, 4, 5, 6, 7, 8, 9))
for range c {
}
}
}
一种用于合并反射:
func BenchmarkMergeReflect(b *testing.B) {
for i := 0; i < b.N; i++ {
c := mergeReflect(asChan(0, 1, 2, 3, 4, 5, 6, 7, 8, 9))
for range c {
}
}
}
最后。一个用于mergeRec:
func BenchmarkMergeRec(b *testing.B) {
for i := 0; i < b.N; i++ {
c := mergeRec(asChan(0, 1, 2, 3, 4, 5, 6, 7, 8, 9))
for range c {
}
}
}
现在我们终于可以运行它们了!
➜ go test -bench=.
goos: darwin
goarch: amd64
pkg: github.com/campoy/justforfunc/27-merging-chans
BenchmarkMerge-4 200000 7074 ns/op
BenchmarkMergeReflect-4 100000 11904 ns/op
BenchmarkMergeRec-4 500000 2475 ns/op
PASS
ok github.com/campoy/justforfunc/27-merging-chans 4.077s
太好了,所以使用递归是最快的选择。让我们暂时相信它!
使用子基准和 b.Run
不幸的是,为了对三个函数进行基准测试,我们重复了很多代码。如果我们可以编写一次基准测试不是很好吗?
我们可以编写一个迭代三个函数的函数:
func BenchmarkMerge(b *testing.B) {
merges := []func(...<-chan int) <-chan int{
merge,
mergeReflect,
mergeRec,
}
for _, merge := range merges {
for i := 0; i < b.N; i++ {
c := merge(asChan(0, 1, 2, 3, 4, 5, 6, 7, 8, 9))
for range c {
}
}
}
}
不幸的是,这只是给出了一个单一且毫无意义的衡量标准,将所有表演混合在一起。
➜ go test -bench=. goos: darwin goarch: amd64 pkg: github.com/campoy/justforfunc/27-merging-chans BenchmarkMerge-4 50000 22440 ns/op PASS ok github.com/campoy/justforfunc/27-merging-chans 1.386s
幸运的是,我们可以通过调用 testing.B.Run 轻松创建子基准测试,类似于使用 testing.T.Run 的子测试。为此,我们需要一个名称,无论如何,从文档的角度来看,这实际上是一个非常好的主意。
func BenchmarkMerge(b *testing.B) {
merges := []struct {
name string
fun func(...<-chan int) <-chan int
}{
{"goroutines", merge},
{"reflect", mergeReflect},
{"recursion", mergeRec},
}
for _, merge := range merges {
b.Run(merge.name, func(b *testing.B) {
for i := 0; i < b.N; i++ {
c := merge.fun(asChan(0, 1, 2, 3, 4, 5, 6, 7, 8, 9))
for range c {
}
}
})
}
}
当我们运行这些基准测试时,我们现在将看到我们希望的三个不同的结果。
➜ go test -bench=. goos: darwin goarch: amd64 pkg: github.com/campoy/justforfunc/27-merging-chans BenchmarkMerge/goroutines-4 200000 6145 ns/op BenchmarkMerge/reflect-4 200000 10962 ns/op BenchmarkMerge/recursion-4 500000 2368 ns/op PASS ok github.com/campoy/justforfunc/27-merging-chans 4.829s
甜的!使用更少的代码,我们仍然能够对我们所有的功能进行基准测试。
对 N 的多个值进行基准测试
到目前为止,我们已经看到对于单个通道,递归算法是最快的,但是 N 的其他值呢?
我们或许可以多次改变 N 的值,看看效果如何。但我们也可以只使用 for 循环!
在下面的代码中,我们从 1 到 1024 迭代 2 的幂,并使用我们要进行基准测试的函数和 N 的值作为基准名称的组合。
func BenchmarkMerge(b *testing.B) {
merges := []struct {
name string
fun func(...<-chan int) <-chan int
}{
{"goroutines", merge},
{"reflect", mergeReflect},
{"recursion", mergeRec},
}
for _, merge := range merges {
for k := 0.; k <= 10; k++ {
n := int(math.Pow(2, k))
b.Run(fmt.Sprintf("%s/%d", merge.name, n), func(b *testing.B) {
for i := 0; i < b.N; i++ {
chans := make([]<-chan int, n)
for j := range chans {
chans[j] = asChan(0, 1, 2, 3, 4, 5, 6, 7, 8, 9)
}
c := merge.fun(chans...)
for range c {
}
}
})
}
}
}
让我们运行基准测试!
➜ go test -bench=. goos: darwin goarch: amd64 pkg: github.com/campoy/justforfunc/27-merging-chans BenchmarkMerge/goroutines/1-4 200000 6919 ns/op BenchmarkMerge/goroutines/2-4 100000 13212 ns/op BenchmarkMerge/goroutines/4-4 50000 25469 ns/op BenchmarkMerge/goroutines/8-4 30000 50819 ns/op BenchmarkMerge/goroutines/16-4 20000 88566 ns/op BenchmarkMerge/goroutines/32-4 10000 162391 ns/op BenchmarkMerge/goroutines/64-4 5000 299955 ns/op BenchmarkMerge/goroutines/128-4 3000 574043 ns/op BenchmarkMerge/goroutines/256-4 1000 1129372 ns/op BenchmarkMerge/goroutines/512-4 1000 2251411 ns/op BenchmarkMerge/goroutines/1024-4 300 4760560 ns/op BenchmarkMerge/reflect/1-4 200000 10868 ns/op BenchmarkMerge/reflect/2-4 100000 22335 ns/op BenchmarkMerge/reflect/4-4 30000 54882 ns/op BenchmarkMerge/reflect/8-4 10000 148218 ns/op BenchmarkMerge/reflect/16-4 3000 543921 ns/op BenchmarkMerge/reflect/32-4 1000 1694021 ns/op BenchmarkMerge/reflect/64-4 200 6102920 ns/op BenchmarkMerge/reflect/128-4 100 22648976 ns/op BenchmarkMerge/reflect/256-4 20 90204929 ns/op BenchmarkMerge/reflect/512-4 3 383579039 ns/op BenchmarkMerge/reflect/1024-4 1 1676544681 ns/op BenchmarkMerge/recursion/1-4 500000 2658 ns/op BenchmarkMerge/recursion/2-4 100000 14707 ns/op BenchmarkMerge/recursion/4-4 30000 44520 ns/op BenchmarkMerge/recursion/8-4 10000 114676 ns/op BenchmarkMerge/recursion/16-4 5000 261880 ns/op BenchmarkMerge/recursion/32-4 3000 560284 ns/op BenchmarkMerge/recursion/64-4 2000 1117642 ns/op BenchmarkMerge/recursion/128-4 1000 2242910 ns/op BenchmarkMerge/recursion/256-4 300 4784719 ns/op BenchmarkMerge/recursion/512-4 100 10044186 ns/op BenchmarkMerge/recursion/1024-4 100 20599475 ns/op PASS ok github.com/campoy/justforfunc/27-merging-chans 61.533s
我们可以看到,尽管递归算法对于单个通道来说是最快的,但具有许多 goroutine 的解决方案非常快,优于其他解决方案。
我们也可以通过使用一些快速 Python 绘制这些数字来实现这一点。别再表现得令人震惊了,我有时也用 Python 写代码!
import matplotlib.pyplot as plt
ns = [2**x for x in range(11)];
data = {
'goroutines': [6919, 13212, 25469, 50819, 88566, 162391, 299955, 574043, 1129372, 2251411, 4760560],
'reflection': [10868, 22335, 54882, 148218, 543921, 1694021, 6102920, 22648976, 90204929, 383579039, 1676544681],
'recursion': [2658, 14707, 44520, 114676, 261880, 560284, 1117642, 2242910, 4784719, 10044186, 20599475],
}
for (label, values) in data.items():
plt.plot(ns, values, label=label)
plt.legend()
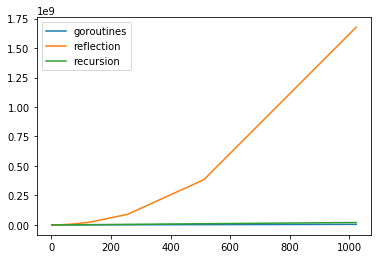
很难看出区别,所以让我们对 Y 轴使用对数刻度(只需添加 plt.yscale('log'))。

管理基准计时器
我们衡量绩效的方式存在一个明显的问题。我们还计算了为我们的测试创建 N 个通道所花费的时间,这增加了与我们的算法无关的成本。
我们可以通过使用 b.StopTimer() 和 b.StartTimer() 来避免这种情况。
for i := 0; i < b.N; i++ {
b.StopTimer()
chans := make([]<-chan int, n)
for j := range chans {
chans[j] = asChan(0, 1, 2, 3, 4, 5, 6, 7, 8, 9)
}
b.StartTimer()
c := merge.fun(chans...)
for range c {
}
}
结果与我们之前的基准测试没有太大不同,但我们可以看到时间差异随着 N 值的增加而增加。
我们能让它们更快吗?
我们终于可以很好地了解每个函数在不同大小的 N 下的表现。这很好,但并不能真正帮助我们使函数更快。
- 登录 发表评论