
数据工程中的生成人工智能
【LLM】LangChian自动评估( Auto-Evaluator )机会
编者按:这是兰斯·马丁的一篇客座博客文章。
TL;DR
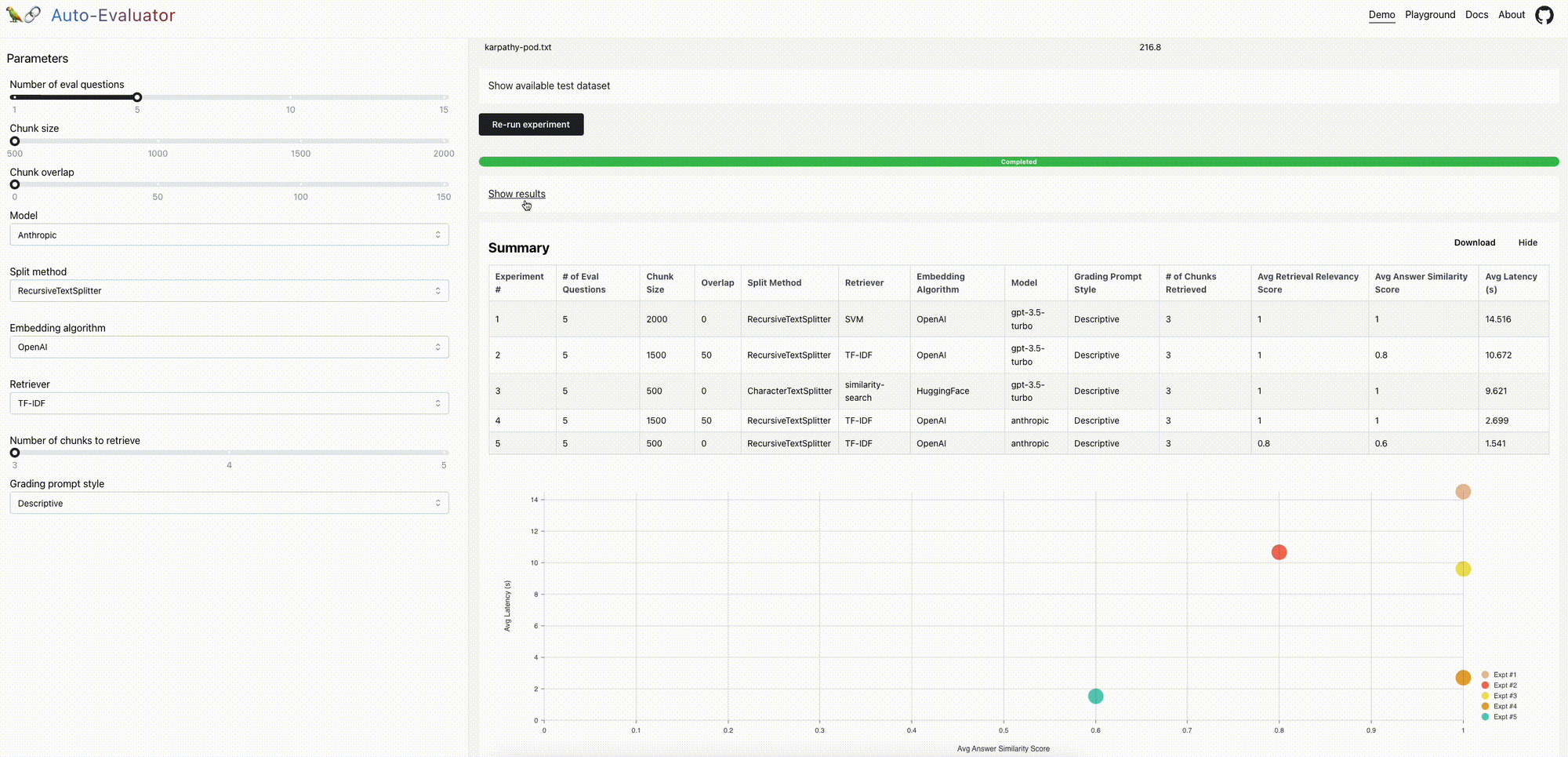
我们最近开源了一个自动评估工具,用于对LLM问答链进行评分。我们现在发布了一个开源、免费的托管应用程序和API,以扩展可用性。下面我们将讨论一些进一步改进的机会。
上下文
文档问答是一个流行的LLM用例。LangChain可以轻松地将LLM组件(例如,模型和检索器)组装成支持问答的链:输入文档被分割成块并存储在检索器中,在给定用户问题的情况下检索相关块并传递给LLM以合成答案。
问题
质量保证系统的质量可能有很大差异;我们已经看到由于特定的参数设置而产生幻觉和回答质量差的情况。但是,(1)评估答案质量和(2)使用此评估来指导改进的QA链设置(例如,块大小、检索到的文档数)或组件(例如,模型或检索器选择)并不总是显而易见的。
【LLM】用LangChain进行问答任务的自动评估
大语言模型
- 阅读更多 关于 大语言模型
- 登录 发表评论
【LLM】利用特定领域知识库中的LLM
通过RAG致富:利用LLM的力量,使用检索增强生成与您的数据对话
问ChatGPT一个关于“马拉松”一词起源的问题,它会准确地告诉你希罗多德是如何描述费迪皮德斯从马拉松到雅典完成的42公里传奇长跑的,然后筋疲力尽。
但我祖母的食谱清单呢?当然,我可以把这些食谱数字化,没问题。但是,如果我想根据冰箱里的食材、我最喜欢的颜色和我一天的心情,就准备哪顿饭提出建议,该怎么办?
让我们看看这是否有可能在不因精疲力竭而崩溃的情况下实现。
LLM,达到你的极限…并超越它们
LLM是一种大型语言模型。OpenAI的GPT-4是一个例子,Meta的LLamA是另一个例子。我们在这里有意识地选择使用一般LLM术语来指代这些模型。请记住:这些模型中的每一个都是在一组庞大的(公开可用的)数据上进行训练的。
到目前为止,已经清楚地表明,这些LLM对通用语言有着有意义的理解,并且他们能够(重新)产生与训练数据中存在的信息相关的信息。这就是为什么像ChatGPT这样的生成工具在回答LLM在培训过程中遇到的主题问题方面表现惊人。
【ChatGPT 】如何使用自己的数据创建私人ChatGPT
了解使用ChatGPT/LLM创建自己的问答引擎所需的体系结构和数据要求。