
category

TL;DR: While the existing LLM app tools like LangChain and LlamaIndex are useful for building LLM apps, their data loading capabilities aren’t recommended outside of initial experimentation. As I built and tested my LLM app pipeline I was able to feel the pain of some of the aspects that are under developed and hacked together. If you’re planning to build a production ready data pipeline to fuel your LLM apps you should heavily consider using an EL tool purpose built for the job.
Introduction
In the last year since OpenAI released ChatGPT there’s been a ton of excitement and a seemingly endless amount of new content and apps being built on top of their technology. As the dust has started to settle from the initial hype we’ve seen the developer ecosystem start to take a step back and assess where we’re at so far. Two recent posts that were shared in the Meltano community piqued our interest and motivated us to do a deeper dive.
The first is a16z’s “Emerging Architectures for LLM Applications” article highlighting the emerging patterns for building Large Language Model (LLM) applications which highlighted the data pre-processing/embedding stage and how “this piece of the stack is relatively underdeveloped, though, and there’s an opportunity for data-replication solutions purpose-built for LLM apps”
The second was this spicey Reddit thread titled “Langchain Is Pointless“ which later hit hacker news as well.
“Why is this just not ETL, why do you need anything here? There is no new category or product needed here.” and “It is pointless – LlamaIndex and LangChain are re-inventing ETL – why use them when you have robust technology already?”

Langchain is grouped in the Orchestration stage by a16z and is one of the main tools used by LLM app developers to do everything from extracting data from sources, to embedding documents and storing them in vector databases, to prompt chaining and storing memory for chat based apps…don’t worry if you dont understand some of these terms, I’ll explain them in the next section.
Inspired by those posts, I went on a deep dive to get a better understanding of what’s going on. I read through tons of articles, watched and listened to lots of youtube videos and podcast (on 2x speed), and built my own LLM chat app for answering questions based on the Meltano SDK docs.
In this blog post I’ll go through the following:
- I’ll give you a summary of what I found when I dug into the LLM app ecosystem and the challenges that come with it
- I’ll do my own read out from a data engineering perspective of how we’ve solved similar problems in the past and propose an ideal architecture
- I’ll explain my POC built using Meltano and a vision for how Meltano could help solve these challenges in the future
Part 1 – A summary of the LLM app ecosystem
I’ll try to do my best to summarize what I’ve found in a concise way so you have enough context about the LLM app ecosystem to see through the jargon. I’ve found that, like a lot of other ecosystems, there’s a lot of abbreviations and jargon but once you peel back the layers it starts to look like common patterns you’ve seen before.
In-context Learning vs Fine Tuning
The first concept that I came across was using fine tuning vs in-context learning + Retrieval Augmented Generation (RAG). The problem that both of these techniques are trying to solve is that the pre-trained LLM’s (like OpenAI’s GPT models or open source alternatives like Hugging Face) were trained on static datasets which are now outdated, this is why when you ask ChatGPT questions about current events it will give you a canned response like “I’m sorry, I was trained on data from 2021…”.
The high level difference between the two is that in-context learning sends context to pre-trained models as part of the prompt at runtime to help it understand more about your question. Whereas fine tuning is further training the pre-trained models to take into account a new set of contextual data then all future prompts go directly to your new iteration of the model.
My takeaway was that for the majority of use cases the in-context learning approach has been the most popular. For more details on in-context learning I’d refer you to the a16z summary but my takeaways are:
- In context learning…
- performs reasonably well for most LLM use cases as part of a RAG pipeline and is the preferred approach
- leverages “off the shelf” tools like OpenAI’s API and Vector databases like Pinecone so a small data team can build an LLM app without having to hire specialized ML engineers
- Fine tuning…
- performs better in narrowly focused contexts when the dataset is large and high quality
- requires more know-how around getting your data to be properly weighted, i.e. not over or under indexing on your content
- requires you to host your own models and infrastructure for serving it
For these reasons I chose to focus primarily on in-context learning apps for the rest of my exploration.
Vector Databases and Embeddings
The next subject that came up was vector databases and embeddings.
A vector database is where your contextual data is stored so that it can be quickly searched at runtime to find semantically similar data for your in-context prompt. This is your knowledge base. Vector databases are not a new technology that came during the LLM wave but they’ve definitely gained a lot of popularity for this use case. Some common ones are Pinecone, Weaviate, Chroma, pgvector Postgres extension, and many others.
I’m not going to go into a lot of detail on how they work, mostly because I don’t know enough 😀 but also because I found that the inner workings of a vector database were too low level and out of scope for this practical understanding of how to use them. Here’s my watered down explanation or how you use vector databases in the context of LLM apps…
The concept is that you convert your source text data (i.e. our SDK docs html text) into embeddings which are large arrays of numbers using an embedding model like OpenAI’s embedding API which you then load into a vector database with the source text used to generate the embeddings attached. For the purposes of building LLM apps you don’t necessarily need to understand the details about what embeddings are and how they’re generated. These text blobs have a size limit so there’s an intermediate step here to chunk them up into smaller subsets. Then when you want to search for similar texts in your chat app you simply embed your input text (again with the OpenAI API) and pass the array to the database as the query. The database takes care of the magic behind retrieving similar vectors and ultimately returning your results which have the original text blobs attached to them. At this point you can collect all the relevant text snippets and use them as context for your new enriched chat prompt.
Langchain
This is the most talked about tool when it comes to building LLM apps. It abstracts away some of these complicated workflows and gives the developer simpler interfaces to build on. There’s debate on whether it does a good job or not but nonetheless that’s the goal. From my view LangChain seems like a nice abstraction for the app layer where things like prompt chaining, memory, and retrieval of context data from vector databases are needed. Although Langchain’s scope starts to go beyond its reach with data connection capabilities that feel like reinventing the wheel in a less production grade way.
LlamaIndex
Similarly there’s tons of mentions of LlamaIndex which has a lot of overlap with LangChain in terms of features and in fact uses LangChain under the hood quite a bit. LlamaIndex apparently has some other nice app level features for building chat apps like context searching, caching, etc. LlamaIndex also has a library of data loaders and tools that are advertised on a sibling project called LlamaHub. Again the main thing that I struggle with is that their scope creeps into that of a data movement tool, their docs say the following in the “Why LlamaIndex?” section:
“Applications built on top of LLMs often require augmenting these models with private or domain-specific data. Unfortunately, that data can be distributed across siloed applications and data stores. It’s behind APIs, in SQL databases, or trapped in PDFs and slide decks.”
So it seems they’re marketing it somewhat as a data movement tool 🤔 but the problem is that they’re reinventing the wheel in a less production grade way. See the slack reader with just a while loop or this medium authors critique that:
“the confluence data loader from Llama is simply a wrapper around the html2text python library and dumps the entire confluence page into a string variable”
Part 2 – What we can learn from Data Engineering
It feels like these projects and the landscape were changing so quickly that nobody had time to stop and consider the scope of the libraries and where the boundaries should be. From my perspective these tools leak into the data engineering space and try to solve problems that have unique challenges and are better left to purpose built data engineering tools.
The data ecosystem has been solving many similar problems over the years so let’s compare the two workflows and find the overlap. Maybe we can take some lessons from DE.
When I think about a summary of what most of these LLM apps are doing, I’d bucket them like this:
- Data extraction – e.g. pull message text from the slack API
- Data cleansing – e.g. remove certain characters, extra spaces, encoding, etc.
- Data enrichment – embedding
- Data loading – write to vector databases
- Application UX i.e. prompt chaining, retrieval, inference, memory, chat UI, etc.
And those buckets look a lot like what a traditional data team has been doing for years:
- Data extraction – e.g. pull data from a variety of sources
- Data enrichment and transformation – e.g. remove duplicates, add consistent names, aggregate complex data into consumable business metrics, etc.
- Data loading – write to a data warehouse
- Data visualization and consumption – charts and dashboards that tell a story about the data
For the purposes of my argument we can drop the application UX because in my opinion that’s the core competency of tools like LangChain and they do it well, use LangChain for that. On the data side we can also drop the data visualization phase because for many data teams the visualization step is passed over to analysts and BI engineers who have the hard job of working with data consumers to interpreting and presenting the data nicely.
That leaves us with the rest of the steps which in both cases can be narrowed down to the following:
- Extraction
- Transform – i.e. Cleaning and Enriching
- Loading
In the data world we’ve iterated on this process over the years, originally calling it Extract Transform Load (ETL) and now transitioning to Extract Load Transform (ELT). The lesson we learned was that extraction is slow and expensive so we only want to do it once whereas the transformation and enrichment step is less expensive and requires more iteration. In addition, over time the cost of storage reduced significantly. Separating storage from compute became a major design consideration. With these realizations we re-designed our systems to decouple the two workflows and now most data teams Extract + Load raw data one time, then transform it many times.
This directly translates to the LLM app world because many teams are experimenting and iterating on the best ways to build their knowledge bases and apps. They’re cleaning their raw data differently, or embedded using different models, or using different vector stores.
What are the most expensive parts of LLM data movement?
If we took this ETL vs ELT learning and applied it to the LLM app development workflow we start to see that it almost directly translates. When the data community was iterating on ETL vs ELT we evaluated the most expensive steps and designed patterns and tools to reduce the impact of them. From my view the most expensive part of the LLM data processing steps are:
- Extracting
- Enriching
Same as for traditional data engineering, extracting from a database or API is slow, expensive, and sometimes painful. In addition to the extraction step, the enrichment step is also expensive especially if you’re using an API like OpenAI’s embedding API. The enrichment step almost starts to look like a second extraction step. Of course there are some ways to reduce the impact of these expensive steps but it’s important to pinpoint the processes that we’re trying to optimize.
Relatable Data Engineering Challenges
At a surface level creating a script that pulls data from an API, cleans and enriches it, then writes it out to some data source seems simple. I’d actually agree. The hard part is all the extra features needed to get it to run reliably and efficiently in production. Some things that data engineers are frequently thinking about and dealing with are:
- Rate limited APIs and outages
- Pagination
- Metadata and logging
- Schema validation and data quality
- Personal Identifiable Information (PII) handling, obfuscation, removal, etc.
- Keeping incremental state between runs so you can pick up where you left off
- Schema change management
- Backfilling data
These LLM libraries currently have capabilities to pull data from an API but are they handling all the challenges related to putting those pipelines in production? The answer is no. But to be fair I don’t think they set out to do this, they built features that users needed at the time, it’s just the nature of fast moving open source projects. Re: LlamaIndex’s slack reader.
How would we design a system around these challenges?
Given all this information I sketched up an example architecture that feels fitting for a workflow like this. The diagram reads from left to right; extracting data from your sources, cleaning and embedding your text, then loading it to the vector database, and with the LLM app itself being out of scope for now.
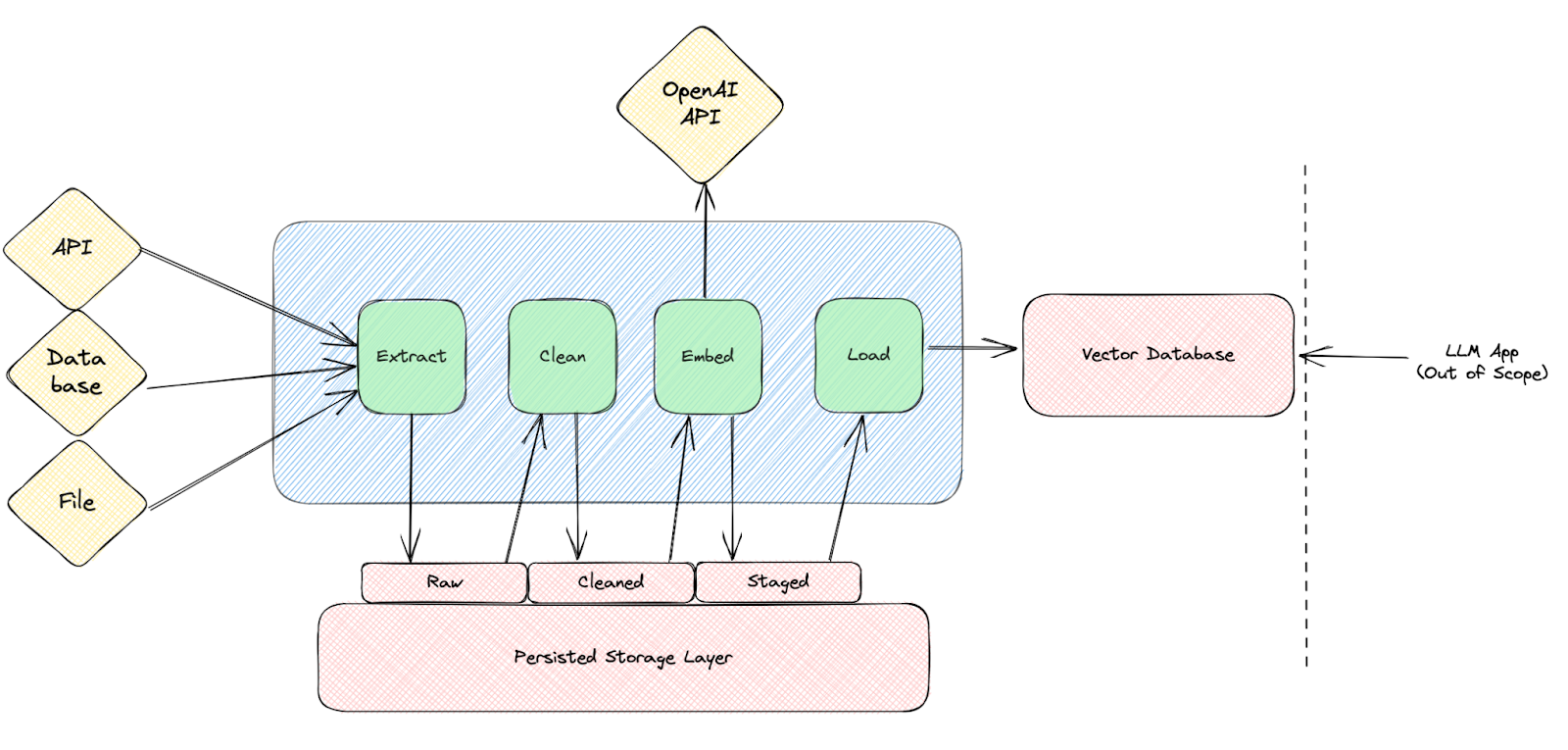
You can see that the main premise is that we’re persisting progress on each step. At first that might seem like extra overhead but especially in a world where we might want to iterate on the cleaning and embedding steps we’ll be very happy to not have to re-extract or re-clean all the source data every time. Additionally given the right tools it should be easy to incrementally update each of these steps in the workflow for only new data since the last run i.e. only retrieve API data from yesterday. With incremental workflows you won’t have to worry so much about API rate limiting, and processing performance because your dataset is much smaller.
Additionally the nature of checkpointing progress at each step allows you to more easily substitute components over time. If you use Pinecone today, you could replace it with Weaviate tomorrow without having to re-extract all your data and create new embeddings once again.
Part 3 – Meltano and LLM Apps
If I’ve convinced you that using data engineering patterns and tools for these workloads is a good idea, we can now talk about why I think Meltano is a good fit. I’ll explain the proof of concept I built using Meltano, and the features that enabled it. Then I’ll talk about how we can iterate on it to make it better in the future. You can also explore the fully functioning demo project on GitHub.
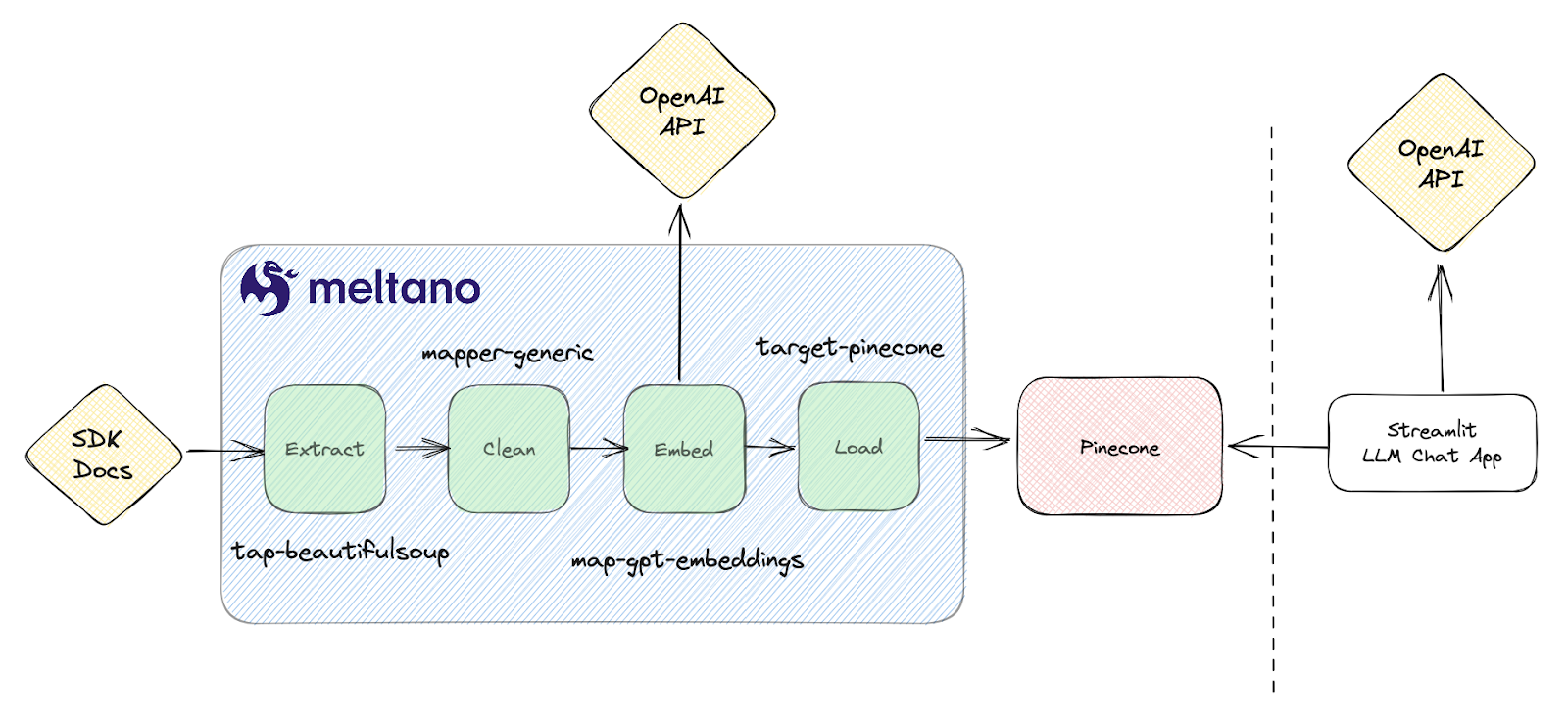
I built a simple pipeline to scrape our Meltano SDK docs site, clean the html, embed it using OpenAI’s embedding API, then load it into Pinecone. This is an iteration on the original. In order to validate my output I also ended up finding a sample Streamlit LLM chat app that retrieves data from my Pinecone index for context and adapted it for my needs. All of this is represented as code in the demo project and is also included in the Meltano Squared project which is deployed in production on Meltano Cloud.
Due to the time constraints of my POC I only implemented a simple end to end sync without the checkpointing features, although the fact that each component is a distinct plugin will allow me to easily extend the project in the future to include robust checkpointing. Other competing tools chose to use Langchain under the hood to chunk, embed, and load vector database data all in one tightly coupled step which I think is a design flaw. Tightly coupling all of these steps and doesn’t allow you to iterate to a more robust design over time.
Each component is a plugin that can be installed and run in a Meltano project so you could recreate this POC without writing any code. You simply add the plugins and configure them for your use case. MeltanoHub also has 600+ plugins to help you pull data from any other source you’d like. Let’s walk through each step.
Extract:
The extract step uses tap-beautifulsoup configured to scrape the SDK docs. It downloads all relevant html pages locally then processes them into individual records with the beautifulsoup library.
meltano.yml
- name: tap-beautifulsoup
variant: meltanolabs
pip_url: git+https://github.com/MeltanoLabs/tap-beautifulsoup.git@v0.1.0
config:
source_name: sdk-docs
site_url: https://sdk.meltano.com/en/latest/
output_folder: output
parser: html.parser
download_recursively: true
find_all_kwargs:
attrs:
role: main
To preview the output you can run meltano invoke tap-beautifulsoup and see output that looks like:
log
2023-08-17T15:28:57.408509Z [info ] Environment 'dev' is active
2023-08-17 11:28:58,886 | INFO | tap-beautifulsoup | Beginning full_table sync of 'page_content'...
{"type": "SCHEMA", "stream": "page_content", "schema": {"properties": {"source": {"type": ["string", "null"]}, "page_content": {"description": "The page content.", "type": ["string", "null"]}, "metadata": {"properties": {"source": {"type": ["string", "null"]}}, "type": ["object", "null"]}}, "type": "object"}, "key_properties": []}
{"type": "RECORD", "stream": "page_content", "record": {"source": "output/sdk.meltano.com/en/latest/typing.html", "page_content": "JSON Schema Helpers#\nClasses and functions to streamline…..[Trimmed Content]", "metadata": {"source": "output/sdk.meltano.com/en/latest/typing.html"}}, "time_extracted": "2023-08-17T15:29:38.975515+00:00"}
Clean:
For this I chose to write a small script with some custom parsing logic to remove extra spaces and new line characters. This script gets executed for each record that’s passed through the pipeline by a Meltano mapper called generic-mapper.
clean_text.py
def map_record_message(self, message_dict: dict) -> t.Iterable[Message]:
page_content = message_dict["record"]["page_content"]
text_nl = " ".join(page_content.split("\n"))
text_spaces = " ".join(text_nl.split())
message_dict["record"]["page_content"] = text_spaces
return message_dict
This mapper allows you to run arbitrary python scripts so you might choose to install the unstructured library as a dependency or Langchain itself to help prep your data in your ideal way.
Generate Embeddings:
In this step we also use a mapper to process each record in the pipeline but this time we use map-gpt-embeddings. This mapper splits the input record into chunks (if needed) then generates embeddings using the OpenAI embeddings API. The mapper uses the Meltano extractor SDK under the hood to leverage all of the nice features like pagination, rate limit handling, etc. with minimal code.
meltano.yml
- name: map-gpt-embeddings
variant: meltanolabs
pip_url: git+https://github.com/MeltanoLabs/map-gpt-embeddings.git
mappings:
- name: add-embeddings
config:
document_text_property: page_content
document_metadata_property: metadata
Load:
Then finally the pipeline uses target-pinecone to write these records to your Pinecone index.
meltano.yml
- name: target-pinecone
variant: meltanolabs
config:
index_name: target-pinecone-index
environment: asia-southeast1-gcp-free
document_text_property: page_content
embeddings_property: embeddings
metadata_property: metadata
pinecone_metadata_text_key: text
load_method: overwrite
These steps are all stitched together as a single scheduled Meltano job but can be run manually using a simple command like `meltano run tap-beautifulsoup clean-text add-embeddings target-pinecone`. You can self-host this if you’d like, or use Meltano Cloud to handle the infrastructure needed to run your predefined schedules.
Future Directions
In the next iteration I’m planning to leverage Singer JSONL extractor and loader to implement the checkpointing features discussed earlier. This will unlock the ability to quickly reload from a checkpoint, preserve data backups, and quickly experiment in the clean + embedding steps (e.g. try different embedding models, cleaning techniques, etc.).
Summary
While the existing LLM app tools like LangChain and LlamaIndex are useful for building LLM apps, they’re data loading capabilities aren’t recommended outside of initial experimentation. As I built and tested my LLM app pipeline I was able to feel the pain of some of the aspects that are under developed and hacked together. If you’re planning to build a production ready data pipeline to fuel your LLM apps you should heavily consider using an EL tool purpose built for the job.
- 登录 发表评论