
这是我们生成人工智能博客系列的第一部分。在这篇文章中,我们讨论了如何使用Ray来生产常见的生成模型工作负载。即将发布的一篇博客将深入探讨Alpa等项目为什么要使用Ray来扩展大型模型。
生成的图像和语言模型有望改变企业的设计、支持、开发等方式。本博客重点关注围绕基础模型支持工作负载生产部署的基础设施挑战,以及Ray,一个用于扩展ML工作负载的领先解决方案,如何应对这些挑战。最后,我们制定了一个改进路线图,以使事情变得更容易。
如今,领先的人工智能组织使用Ray大规模训练大型语言模型(LLM)(例如,OpenAI训练ChatGPT,Cohere训练其模型,EleutherAI训练GPT-J,Alpa训练多节点训练和服务)。然而,这些模型之所以如此令人兴奋,其中一个原因是可以对开源版本进行微调和部署,以解决特定问题,而无需从头开始训练。事实上,社区中的用户越来越多地询问如何使用Ray来协调他们自己的生成人工智能工作负载,建立由大型玩家训练的基础模型。
在下表中,我们用绿色突出显示了常见的“生产规模”需求(通常从1-100个节点开始)。这包括以下问题:
- 如何将批量推理扩展到数TB的非结构化数据?
- 我如何创建一个微调服务,可以根据需要创造新的工作岗位?
- 如何在多个节点上部署跨多个GPU的模型?
在这篇博客文章中,我们将主要关注这些绿色突出显示的工作负载。

Different scale workloads for generative AI.
如果您有兴趣了解使用Ray进行生成人工智能工作负载的代码示例,请查看我们的示例页面。
生成模型:ML工作负载的最新发展
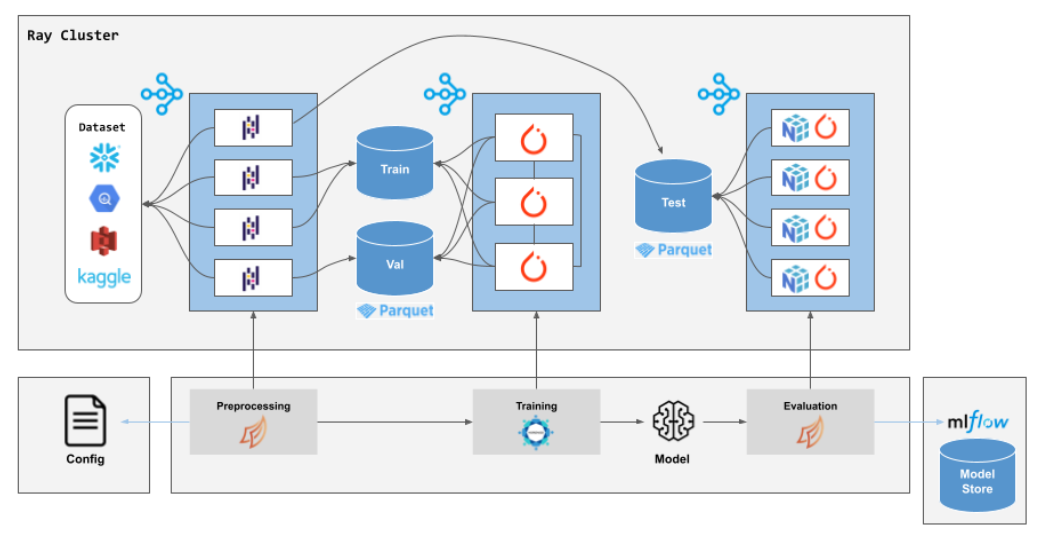
Fig. Based on the latest deep learning models, the compute requirements of generative AI mirror those of traditional ML platforms, only greater.
我们认为生成模型工作负载放大了ML工作负载背后固有的计算挑战。这是沿着两个轴来的:
- 成本:生成模型更大,训练和服务的计算成本更高。例如,XGBoost/scikit学习模型每个记录可能需要1-10ms,而对这些生成模型的最基本推断将需要1000ms或更多——这是>100x的因子。这种成本的变化使得分布式成为那些希望在生产中使用生成模型的公司的默认要求。
- 复杂性:部分由于成本的原因,文本生成和图像扩散等用例中出现了新的计算需求,如模型并行服务或增量状态更新(即报告部分结果)。
让我们更具体地按工作量来细分这一趋势。下表总结了常见的人工智能工作负载,以及这些不同用例的基础设施需求是如何随着时间的推移而演变的:

如表所示,这些工作负载的成本和复杂性随着时间的推移而增长——尽管该行业的GPU硬件得到了快速改进。接下来,让我们深入探讨从业者在使用生成人工智能处理这些工作负载时可能面临的挑战。
生成型人工智能基础设施面临的挑战
生成型人工智能基础设施为分布式培训、在线服务和离线推理工作负载带来了新的挑战。
1.分布式培训
目前,Ray正在进行一些规模最大的生成模型训练:
- OpenAI使用Ray来协调ChatGPT和其他模型的训练。
- Alpa project 项目使用Ray来协调数据、模型和管道并行计算的训练和服务,并将JAX作为底层框架。
- Cohere和 EleutherAI 使用Ray与PyTorch和JAX一起大规模训练他们的大型语言模型。
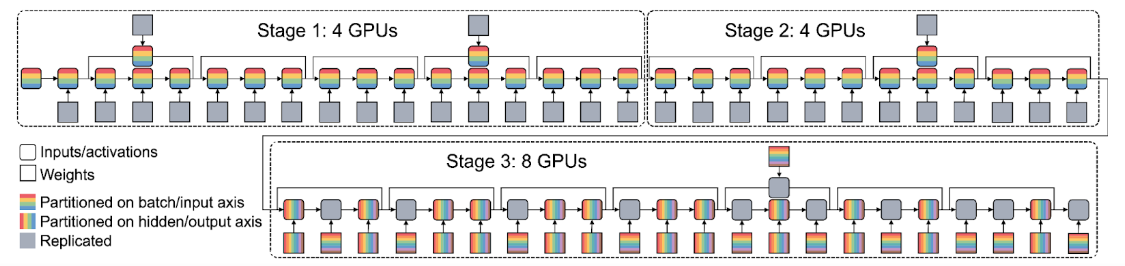
Fig. Alpa uses Ray as the underlying substrate to schedule GPUs for distributed training of large models, including generative AI models.
生成模型分布式训练的常见挑战包括:
- 如何在多个加速器之间有效地划分模型?
- 如何设置您的培训以容忍可抢占实例上的失败?
在即将发布的博客中,我们将介绍项目如何利用Ray来解决分布式培训的挑战。
2.在线服务和微调
我们还看到,人们越来越感兴趣地将Ray用于中等规模(例如1-100个节点)的生成人工智能工作负载。通常,这种规模的用户有兴趣使用Ray来扩展他们已经可以在一个节点上运行的现有训练或推理工作负载(例如,使用DeepSpeed、Accelerate或各种其他常见的单节点框架)。换句话说,为了部署在线推理、微调或培训服务,他们希望运行工作负载的许多副本。
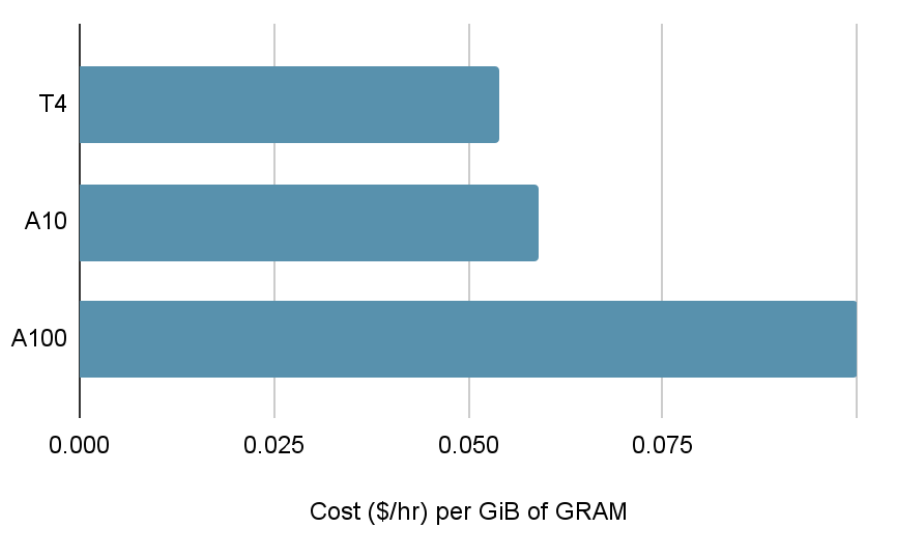
Fig. A100 GPUs, while providing much more GRAM per GPU, cost much more per gigabyte of GPU memory than A10 or T4 GPUs. Multi-node Ray clusters can hence serve generative workloads at a significantly lower cost when GRAM is the bottleneck.
这种形式的扩展本身可能非常棘手,而且实施起来成本高昂。例如,考虑为多节点语言模型扩展微调或在线推理服务的任务。有许多细节需要解决,例如优化数据移动、容错和自动缩放模型副本。DeepSpeed和Accelerate等框架处理模型运算符的分片,但不处理调用这些模型的高级应用程序的执行。
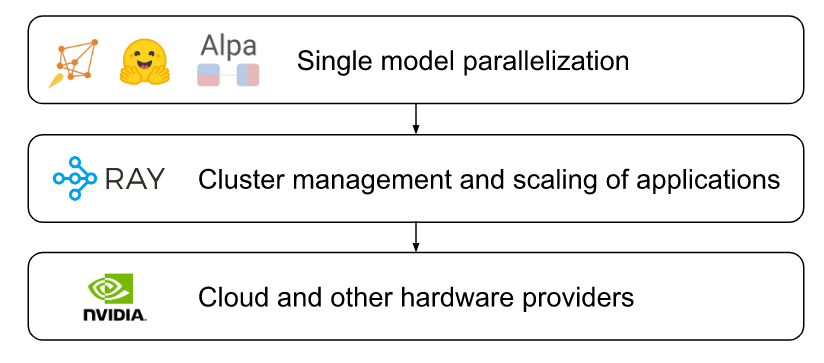
Fig. Layered stack diagram for deployments of generative model workloads.
即使对于单节点工作负载,用户也经常可以从分发中受益,因为部署小型GPU集群比部署单个高端设备(例如A100 GPU)用于托管模型要便宜得多。这是因为低端GPU通常每GB内存的成本更低。然而,要扩展涉及多台机器的部署是很有挑战性的。如果没有像Ray Serve和Ray Data这样的库,也很难实现开箱即用的高利用率。
3.离线批量推理
在离线方面,这些模型的批量推理也面临着需要数据密集型预处理和GPU密集型模型评估的挑战。Meta和谷歌等公司构建自定义服务(DPP,tf.data服务),以在异构CPU/GPU集群中大规模执行此功能。虽然在过去,这样的服务很少见,但我们越来越多地看到用户询问如何在生成人工智能推理的背景下做到这一点。这些用户现在还需要解决分布式系统在调度、可观察性和容错方面的挑战。
Ray如何应对这些挑战
现有Ray功能
- Ray Core调度:为了协调从头开始训练生成模型所需的大规模分布式计算,Ray Core灵活地支持在CPU和GPU上调度任务和参与者。对于那些使用Ray进行大规模模型训练的人来说,这一功能尤其有用。放置组允许用户保留GPU或CPU资源组,以放置大型模型的副本,用于多节点微调、推理或训练。
- Ray Train:Ray的Train库提供了开箱即用的Trainer类,这些类可以运行流行的框架,如分布式TensorFlow、Torch、XGBoost、Horovod等。为了更容易开始使用生成模型,我们添加了与流行框架的集成,如HuggingFace Accelerate、DeepSpeed和Alpa To Train,以及RLHF支持。
- Ray Serve:Ray Serve为缩放模型部署图提供了一流的API。因为Serve在Ray中运行,所以它在运行特别或辅助计算方面也有很大的灵活性。例如,用户从Serve启动Ray子任务来微调模型,并通过同样在Ray中运行的命名参与者来协调增量结果的返回。
即将推出的功能
- Ray Data流后端:为了使混合CPU和GPU节点集群上的大规模批量推理更容易大规模运行,我们正在努力为Ray Data添加一流的流媒体推理支持:https://github.com/ray-project/enhancements/pull/18
- Ray Serve中的异步请求:我们希望增强Ray Serve,以本地处理长时间运行的异步作业,如微调请求。这些请求通常需要几分钟的时间才能运行,比<10秒的正常ML推理作业要长得多,这通常意味着用户必须转向使用外部作业队列:https://github.com/ray-project/ray/issues/32292
我们正在发布的新示例
当然,在理论上可行和在实践中可行之间存在很大的区别。为了弥补这一差距,我们还宣布了几个生成性人工智能示例的初步发布,随着新模型和框架的出现,我们将随着时间的推移进行扩展。
链接的示例可能需要您使用Ray的夜间版本——链接和示例将在Ray 2.4的稳定版本上提供。
-
Stable Diffusion
-
Streaming Batch Prediction: coming in Ray 2.5
-
GPT-J
-
Streaming Batch Prediction: coming in Ray 2.5
-
OPT-66B
-
Fine-Tuning: coming in Ray 2.5
-
Serving: coming in Ray 2.5
-
Batch Prediction: coming in Ray 2.5
-
Streaming Batch Prediction: coming in Ray 2.5
-
结论
总之,我们认为生成模型正在加速对灵活、统一的框架(如Ray)的需求,以运行ML计算。Ray团队计划添加增强的API,用于大规模处理这些类型的昂贵模型和示例,以及与流行模型和社区框架的集成,使其易于入门。在这里开始学习Ray ML用例,并在我们的示例页面上查看我们使用Ray进行生成人工智能工作负载的代码示例。
- 登录 发表评论