【LLM】LangChain 利用上下文压缩改进文档检索
pgmr.cloud
12 May 2023
注意:这篇文章假设你对LangChain有一定的熟悉程度,并且是适度的技术性文章。
💡 TL;DR:我们引入了新的抽象和新的文档检索器,以便于对检索到的文档进行后处理。具体来说,新的抽象使得获取一组检索到的文档并仅从中提取与给定查询相关的信息变得容易。
介绍
许多LLM支持的应用程序需要一些可查询的文档存储,以便检索尚未烘焙到LLM中的特定于应用程序的信息。
假设你想创建一个聊天机器人,可以回答有关你个人笔记的问题。一种简单的方法是将笔记嵌入大小相等的块中,并将嵌入的内容存储在向量存储中。当你问系统一个问题时,它会嵌入你的问题,在向量存储中执行相似性搜索,检索最相关的文档(文本块),并将它们附加到LLM提示中。
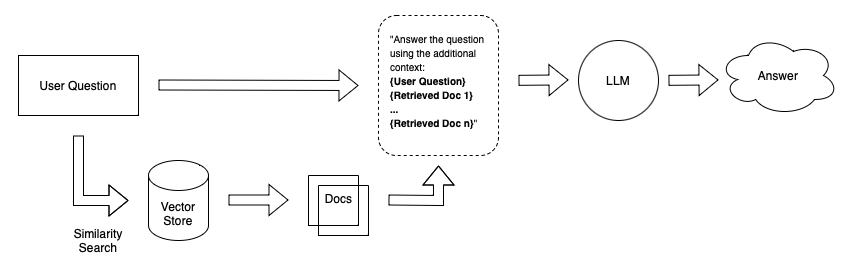
A simple retrieval Q&A system
【LLM】用LangChain进行问答任务的自动评估
pgmr.cloud
12 May 2023
【LLM】用LlamaIndex建立和评估QA保证体系
pgmr.cloud
10 May 2023
介绍
LlamaIndex(GPT Index)提供了一个将大型语言模型(LLM)与外部数据连接起来的接口。LlamaIndex提供了各种数据结构来索引数据,如列表索引、向量索引、关键字索引和树索引。它提供了高级API和低级API——高级API允许您仅用五行代码构建问题解答(QA)系统,而低级API允许您定制检索和合成的各个方面。
然而,将这些系统投入生产需要仔细评估整个系统的性能,即给定输入的输出质量。检索增强生成的评估可能具有挑战性,因为用户需要针对给定的上下文提出相关问题的数据集。为了克服这些障碍,LlamaIndex提供了问题生成和无标签评估模块。
在本博客中,我们将讨论使用问题生成和评估模块的三步评估过程:
- 从文档生成问题
- 使用LlamaIndex QueryEngine抽象生成问题的答案/源节点,该抽象管理LLM和数据索引之间的交互。
- 评估问题(查询)、答案和源节点是否匹配/内联