
pgmr.cloud
20 May 2023
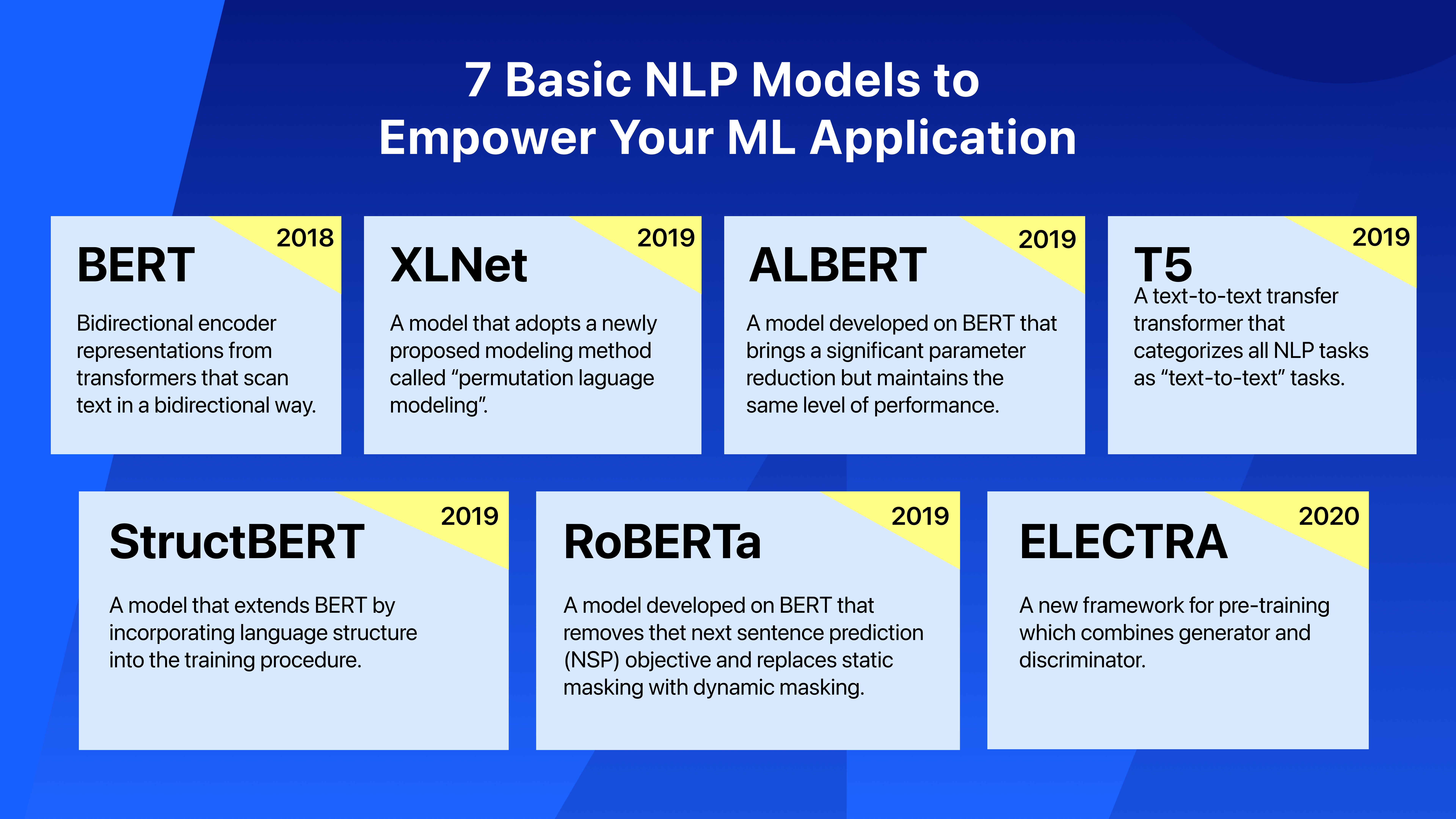
在上一篇文章中,我们已经解释了什么是NLP及其在现实世界中的应用。在这篇文章中,我们将继续介绍NLP应用程序中使用的一些主要深度学习模型。
BERT
- 来自变压器的双向编码器表示(BERT)由Jacob Devlin在2018年的论文《BERT:用于语言理解的深度双向变压器的预训练》中首次提出。
- BERT模型的主要突破是,它在训练过程中查看文本时,以双向方式扫描文本,而不是从左到右或从左到左和从右到左的组合序列。
- BERT一般有两种类型:BERT(基本)和BERT(大)。不同之处在于可配置参数:基本参数为1100万,大参数为3.45亿。
XLNet
- XLNet于2019年发表在论文《XLNet:语言理解的广义自回归预训练》中。
- XLNet在20次基准测试中以很大的优势优于BERT,因为它利用了自回归模型和双向上下文建模的最佳效果。XLNet采用了一种新提出的建模方法,称为“置换语言建模”。
- 与基于前一个标记的上下文预测句子中单词的语言模型中的传统标记化不同,XLNet的置换语言建模考虑了标记之间的相互依赖性。
- XLNet的性能测试结果比BERT提高了2-15%。
RoBERTa
- RoBERTa是在2019年的论文《RoBERTa:一种稳健优化的BERT预训练方法》中提出的。
- RoBERTa对BERT的体系结构和培训程序进行了更改。具体而言,RoBERTa删除了下一句预测(NSP)目标,使用了比BERT大得多的数据集,并用动态掩蔽取代了静态掩蔽。
- RoBERTa的性能测试结果比BERT提高了2-20%。
ALBERT
- ALBERT模型是在2019年的论文《ALBERT:语言表征自我监督学习的精简BERT》中提出的。
- ALBERT是在BERT模型的基础上开发的。它的主要突破是显著降低了参数,但与BERT相比保持了相同的性能水平。
- 在ALBERT中,参数在12层变压器编码器之间共享,而在原始BERT中每层编码器都有一组唯一的参数。
StructBERT
- StructBERT是在2019年的论文《StructBERT:将语言结构纳入深度语言理解的预训练》中提出的。
- StructBERT通过将语言结构纳入训练过程,进一步扩展了BERT。
- StructBERT还引入了单词结构目标(WSO),它有助于模型学习单词的排序。
T5
- T5是在2019年的论文《用统一的文本到文本转换器探索迁移学习的极限》中介绍的。T5是“文本到文本传输转换器”的缩写。
- T5发布了一个干净、庞大、开源的数据集C4(Colossal clean Crawled Corpus)。
- T5将所有NLP任务分类为“文本到文本”任务。
- T5型号有五种不同尺寸,每种型号都有不同数量的参数:T5小型(6000万个参数)、T5基础(2.2亿个参数),T5大型(7.7亿个参数。
ELECTRA
- ELECTRA是在2020年的论文“ELECTRA:将文本编码器预训练为鉴别器而非生成器”中提出的。
- ELECTRA提出了一种新的预训练框架,它结合了生成器和鉴别器。
- ELECTRA将掩蔽语言模型的训练方法改为替换标记检测。
- ELECTRA在小型模型上表现更好。
- 登录 发表评论