
category

In the previous part, we covered basic architecture concepts for using Large Language Models (LLMs) like GPT inside smart features and products. Today, we focus on how our application can interpret the completion before returning a response to the user.
Table of Contents
1. Overview
2. Asking for JSON completions
3. Managing output consistency
4. Function calling
5. Tools (plugins)
01. Overview
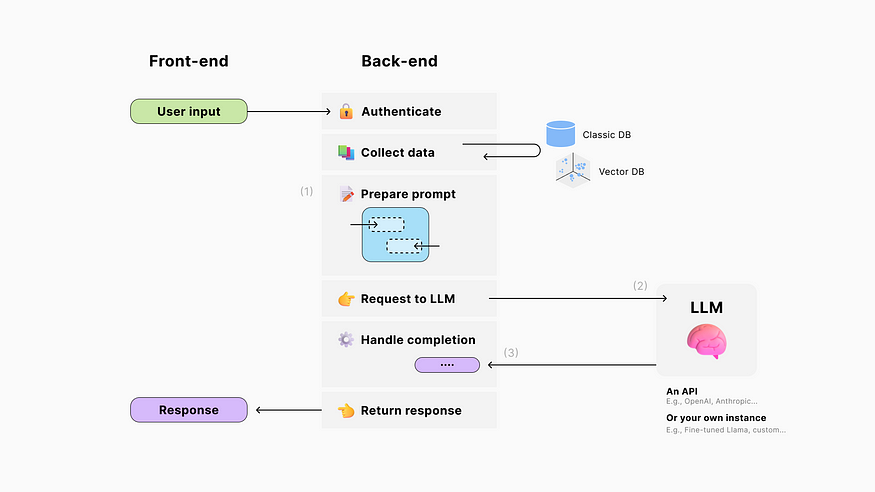
After we’ve (1) prepared our prompt and (2) sent it to the LLM to generate a response, (3) our application can read the completion to determine follow-up actions like triggering events, executing functions, calling databases, or making other LLM requests.
02. Asking for JSON completions
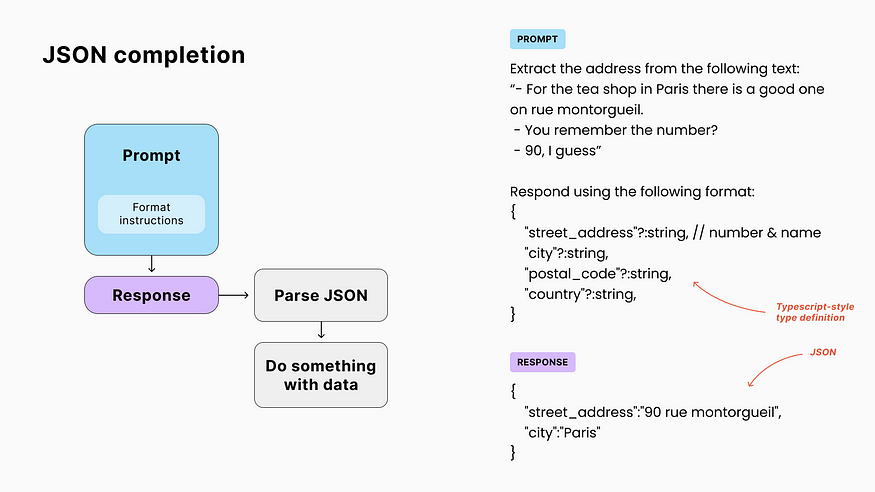
To programmatically trigger actions based on the LLM’s response, we don’t want to play a guessing game, trying to discern intent through scattered words and phrases in the completion.
A more reliable solution is to prompt the model to respond in JSON, which is a widely-used text format for representing structured data, supported by all major programming languages, and human-readable. 🧐
Here is an example of JSON describing criteria for a trip:
{
"departureCity": "New York, USA",
"destination": "Paris, France",
"numberOfTravelers": 2,
"businessTrip": false,
"specialRequests": [
"Room with view of eiffel tower",
"Guided tour arrangements"
],
"budgetRange": {
"min": 3000,
"max": 4000
}
}
Describing our desired structure
Letting the AI improvize the data structure won’t be reliable or actionable. Our prompt must describe what we’re looking for.
💡 For this purpose, even if we want JSON outputs, the common practice with GPT is to use Typescript-style type definition. A simple syntax that can describe data types (text strings, numbers, booleans, etc.), optional properties (using ?), and comments to guide the LLM (starting with //).
This “technical” prompt engineering might require someone with coding knowledge. 🤝 But if multiple people work on different parts of your prompts, make sure they collaborate closely, as their instructions could potentially interfere with one another.
03. Managing output consistency
The amazing non-deterministic capabilities of LLMs come at a cost: they do not always follow format instructions. 😩 There are several factors at play:
Code fluency of the model
The less code your model was initially trained on, the wordier instruction it might require. If it didn’t learn any at all, I don’t think you make up for that with prompting.
Fine-tuning
On the other hand, if you fine-tune an LLM with only examples of the JSON structure you’re looking for, it will learn to do this task and won’t require format instruction anymore.
Prompt engineering
With capable enough models like GPT, output consistency can still be influenced by:
- The phrasing of the instruction
- The position of the instructions in the prompt
- And the rest of the prompt/chat history, as they could contain sentences that confuse the model.
👍 Tips with GPT:
- When using large prompts, place your format instructions at the end, close to the expected response.
- Ask the model to wrap the JSON between the
```jsonand```Markdown delimiters, which seem to help it write valid code and facilitate the extraction. - Get inspiration from tools like LangChain‘s Structured Output Parser, but ensure it fits your specific needs and the model you use.
Hot take on LangChain 🦜🔥
LangChain is the most popular Python/JavaScript framework simplifying the development LLM applications by providing plug-and-play prompt chaining, RAG, agents/tools, along with multi-AI-provider support.
The community behind it curates prompts and architecture best practices from the latest research papers. It’s a great source of inspiration, ideal for prototyping and solving common use cases (e.g., chat with a knowledge base).
But I consider that real-life production applications require more control of your system, which is not rocket science BTW (and the reason for this series of articles). 🤓
Using LangChain, you are dependent on their underlying choices and updates like this format-instructions prompt that doubled in token size in May (see before and after). If you’re only using GPT, it doesn’t need to be explained what JSON is. You’re just paying extra tokens, reducing your context window, and risking confusing the model’s attention. 🍗🙄
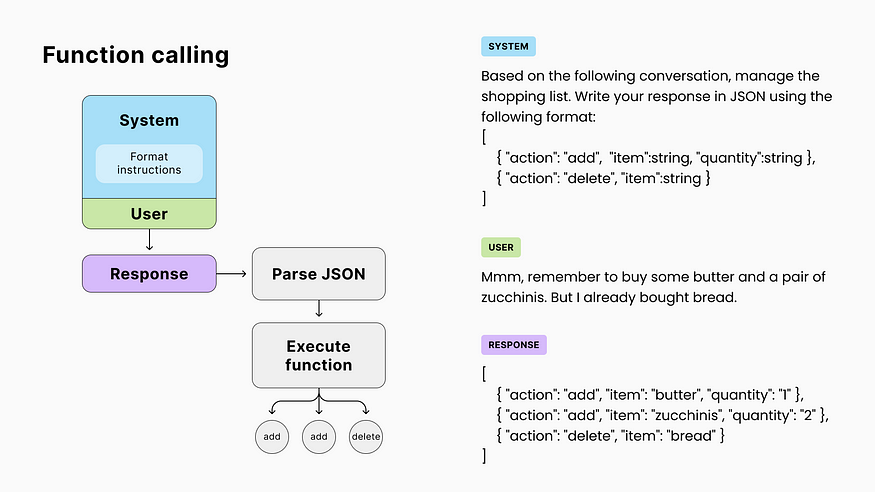
04. Function calling
Let’s go back to our app! Now, if we prompt the model with a list of possible actions and request a JSON-formatted completion, our app can easily interpret it and execute the corresponding code for each action.
This allows the AI to interact with various components of our application (memory, database, API calls, etc.)
Security concerns
Obviously, if uncontrolled, letting a non-deterministic AI play with your system exposes you to security issues like prompt injection (a hacker crafting a message that gets the model to do what they want). To alleviate that:
- Avoid letting the AI execute arbitrary code like running its own SQL queries. Instead, limit its interactions to a set of preapproved actions.
- Execute AI actions with user-level permissions to make sure it cannot access data from other users.
- Make sure you understand what AI tools can do before using them. Engineering expertise and critical thinking are crucial here.
OpenAI’s function calling
In June 2023, OpenAI released access to their GPT function-calling feature, which, much like chat prompts, introduced a new proprietary API syntax abstracting what could already be done with prompting, coupled with a fine-tuning of their model for more reliability.
☝ Their implementation is reliable but not yet a standard across AI models and providers. Just like LangChain, it represents a tradeoff between ease of use and control over your tech.
05. Tools (plugins)
Combining JSON responses, function calling, and prompt chaining, we can assemble a smart assistant able to complete tasks involving external resources.
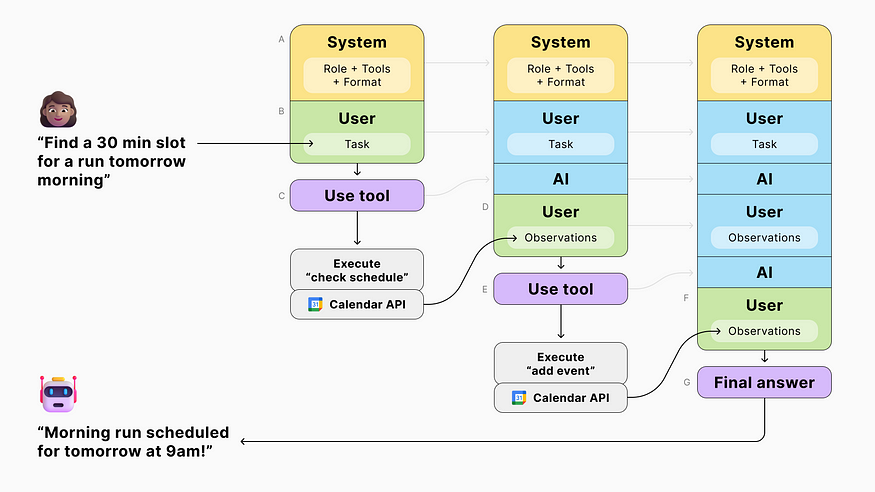
- We start by running a first LLM query, providing the model with a task and a set of tools.
- Based on its response, we execute the corresponding function and feed the result back to the model in a subsequent query.
- And we repeat the process, letting the AI decide on the next step until it reaches a final answer.
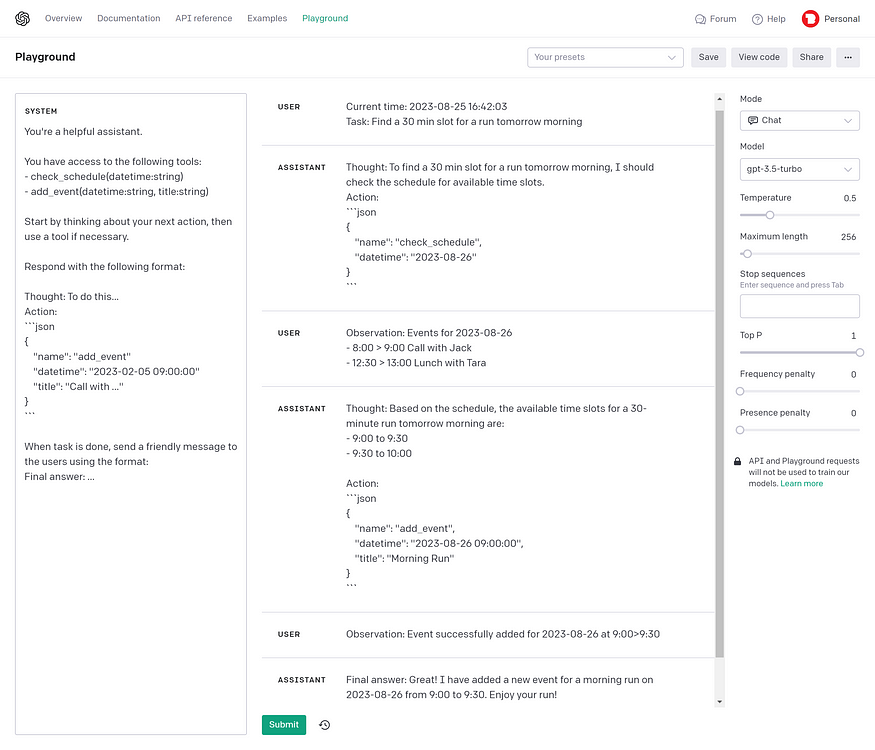
👀 With GPT chat prompts, I use “user” messages for everything that represents the environment perceived by the AI, even if it’s not a message from the user. It seems more natural with the way the model was fine-tuned.
🙃 I didn’t use Typescript-style format instruction here because the JSON is part of an example (few-shot prompting) and didn’t require optional properties or comments. The only rule is to experiment and find what’s appropriate for your specific use case.
🧠 Prompting the AI to verbalize its thought process is known to radically increase the output’s quality. This technique is called Chain of Thought.
📆 The LLM doesn’t know the current date and time. If your use case requires it, add it to your prompt (just like ChatGPT).
👩🏽 Finally, you don’t need to show the user all of the AI's internal thoughts. But you can reduce waiting time perception by giving action feedback (e.g., “checking calendar”), just like ChatGPT does with their plugins.
- 登录 发表评论