
category

Editor's Note: this blog was written by Michael Liebmann and Volodymyr Machula, co-founders of Connery. Connery is an open-source framework for creating integrations as plugins usable across many platforms, including as tools for LLM-powered agents!
Over the past decade, Volodymyr and I have created all sorts of integrations. This includes everything from traditional system integrations and customizations to creating plugins for LLM applications, CI/CD workflows, Slack, and no-code tools.
It’s always been the same pain points. So, we decided to make a change and wrap our experience into an open-source project called Connery, allowing everyone to benefit from it!
Connery provides a plugin infrastructure tailored for LLM applications, enabling easy integration with third-party services and customizing them. It manages the runtime, integrates seamlessly with OpenGPTs, and provides a user interface for connection management, personalization, and safety.
In addition, Connery is building out tooling and developer experience for an open-source plugin ecosystem. The goal is to allow the community to benefit from creating, sharing, and customizing each others’ plugins.
Problem: Integrating LLMs with Real-World Applications
LLM-based apps, like chatbots and assistants, are becoming increasingly useful for reasoning or generative tasks. However, enabling LLM apps to directly execute real-world tasks is a much larger opportunity. While this is still a struggle, there is no question that this is becoming a major trend.
Applications for general use, like business or personal assistants (think of something similar to Tony Stark's J.A.R.V.I.S.), may need numerous integrations with external systems. Likewise, agents focused on specific fields like DevOps, HR, finance, or shopping become more effective when they can perform real-world tasks.
However, compared to conventional applications, LLM-based apps are somewhat unpredictable due to potential hallucinations and incorrect decisions. Consequently, integrating LLMs into real-world scenarios demands additional safety measures and extra consideration.
Moreover, building and running integrations is generally complex. It's even more so with integrations into LLM-based apps that require a specialized infrastructure.
Below, we list some important challenges you need to consider as a developer while integrating your LLM-based app with the real world.
Personalization and security
Personalization of LLM apps is an important driver for AI development in 2024. This allows LLMs to bring more individual value to their users. It also means an LLM app can directly interact with the users’ individual services, such as sending emails, accessing calendars, etc. This requires essential integration and personalization features:
- User authentication, authorization, and a user interface to manage connections and personalization.
- Connection management: Users need a secure way to authorize AI-powered apps to access their services, such as Gmail, using OAuth. For services not supporting OAuth, like AWS, secure storage of access keys is essential through Secrets Management.
- Personalization: The user can configure and personalize integrations. For example, specify a custom signature for all the emails. Or personalize metadata for actions so LLMs better understand the personal use case. They can also provide personal information such as name and email so LLMs can use it as additional context when calling actions.
AI safety and control
Traditional applications have well-defined functions that can be predicted and tested, ensuring consistent operation. In contrast, LLM-based apps are unpredictable due to their natural language capabilities, leading to potential risks like misinterpreted commands. To mitigate this, additional measures are needed:
- Metadata allows LLMs to better understand available actions and consequently reduce the error rate in selecting and executing them. It includes an action description with a clear purpose, an input schema describing the available parameters and validation rules, and the action outcome.
- Human-in-the-loop capability to empower the user with the final say in executing actions for critical workflows. This should also allow for editing suggested input parameters before running an action - for example, reviewing an email before sending.
- Audit logs for consistency, compliance, and transparency.
Infrastructure for integrations
LangChain provides a great framework for building LLM applications. On the other hand, adding integrations into such LLM apps is quite different and comes with its own complexity.
Currently, developers need to build their own custom integration infrastructure within their app in order to integrate it with the real world. This includes:
- Authorization for integrations with third-party services using OAuth, API Keys, etc.
- Support different integration types and patterns like CRUD operations, async operations, event-driven operations, etc.
- Support integration code and its runtime
Most of these items are a hassle when building LLM-powered apps with integrations and distract builders from their main goals.
Proposed solution: open-source plugin infrastructure and ecosystem
To address the problems mentioned above, we believe building a plugin infrastructure for LLM apps and GPTs with the following characteristics is the best approach:
- First, it must be open-source.
- Second, it must have a collaboration model.
We hope this will grow into an open plugin community and facilitate speed and innovation, unlike many closed-source approaches. This is our primary driver for why and how we build Connery.
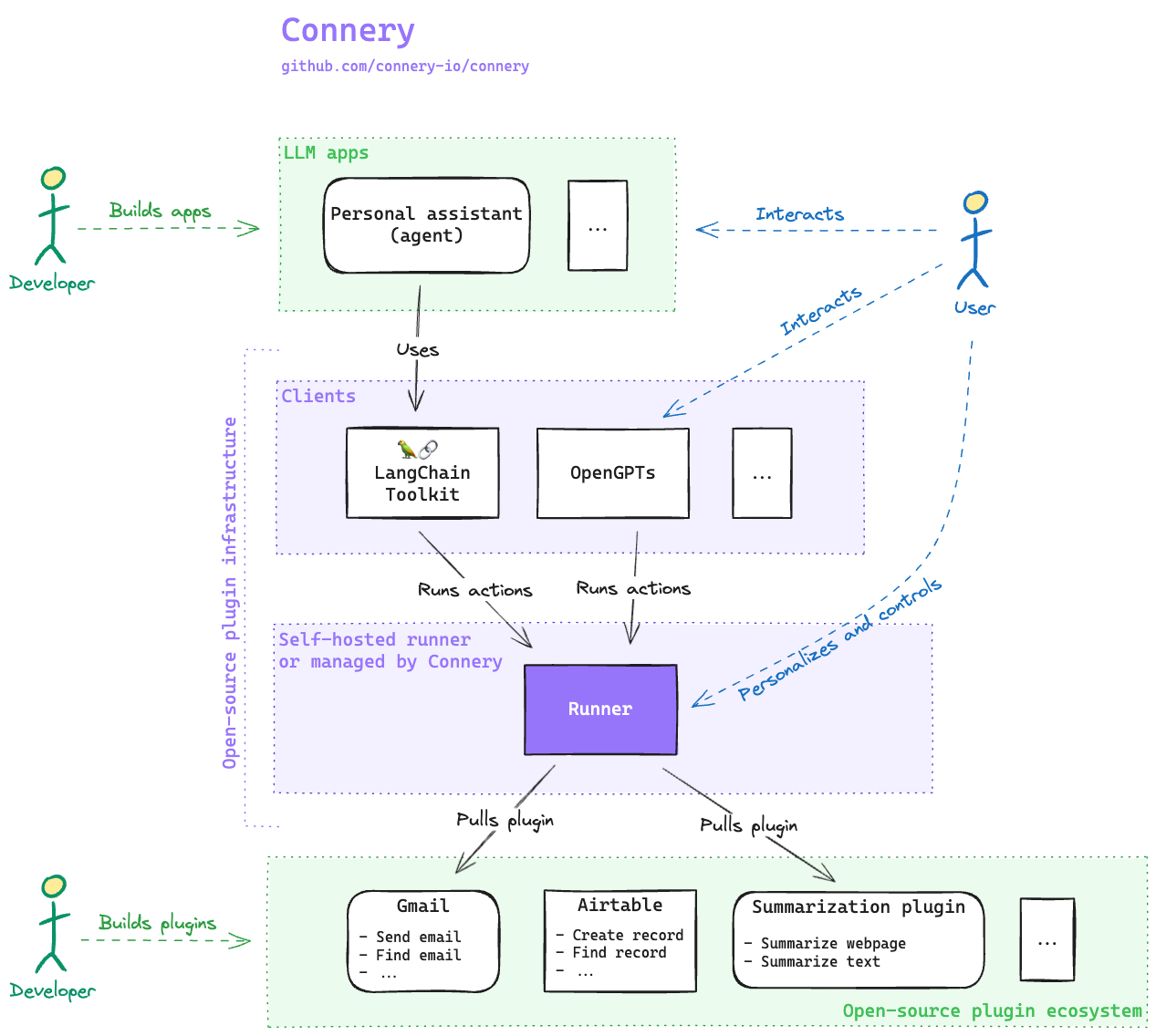
We'll go over the subcomponents of each component in the above diagram next.
Plugin ecosystem
On the ecosystem side, we have two pieces:
- Actions - think of an action as a basic task, something like a function with input and output parameters designed to do one specific thing. For example, "Send email" is an action in the "Gmail" plugin.
- Plugins are a collection of related actions. Each plugin is represented by an open-source GitHub repository with TypeScript code of a specific structure. A plugin must be installed on the Runner before its actions can be used.
💡
For the rest of the article, we will be using the term plugin instead of integration. That is because a plugin is more than an integration. It is a self-contained module that comes with a specific set of features to simplify and improve the integration of third-party APIs (more details below).
Plugin infrastructure
- The Runner is the heart of Connery. It's an open-source engine that integrates plugins from GitHub. It’s equipped with a user interface and a set of features for connection management, personalization, and safety. Everyone can set up their own isolated Runner, uniquely configured with a set of plugins and a standardized API for clients.
- Clients are the user-facing aspect of Connery, serving as the interface through which end-users can trigger actions. OpenGPTs from LangChain, for example, allow the end users to deeply customize and personalize their GPTs by connecting them to the real world with Connery actions. Connery also provides Clients for many other platforms.
Developer and user perspectives
- Developers have the flexibility to create their own plugins or utilize existing ones from the community. Plugins can easily be integrated into LLM apps, like chatbots or assistants, through Connery clients, e.g., OpenGPTs, a LangChain Toolkit, API, or others.
- End-users of the LLM app first personalize their experience on the Runner by connecting to their personal accounts, like Gmail, and providing other personal information. Then, authorize the LLM app to use the personalized Runner. Once done, the user can ask the LLM app to execute actions on their behalf, like sending emails, still controlling what the app does, and having the final say if needed.
Example: Running Connery actions from OpenGPTs
The recent updates to LangChains OpenGPTs provide support for different cognitive architectures. The new ‘assistants’ feature offers an easy method for integrating tools, such as Connery actions, into custom GPTs. Let's jump into a brief example:
Summarize a webpage and send it by email
Imagine you've found an insightful article on Paul Graham's website and want to share a concise summary of it with a colleague via email. This could involve two actions from two different plugins:
- Summarize public webpage action from the Summarization plugin. This action takes a public webpage URL and generates a brief summary of the article using OpenAI.
- Send email action from the Gmail plugin. It takes the recipient, subject, and body as input parameters and sends the email to the recipient.
Try demo
Here, you'll find a demo version of OpenGPTs hosted by LangChain. It comes with a preconfigured Connery Runner and all the necessary actions for our demo. You can summarize any article you like and send it to your email, like in the following video (note that for demo purposes, the context window has a 16K token limit):
Summarize a webpage and send it by email from OpenGPTs using Connery actions
What happens behind the scenes?
Below is a simplified process of what happens behind the scenes in the demo:
- The User sends a request to the OpenGPT by submitting a prompt.
- OpenGPT pulls actions: The OpenGPT connects to Connery Runner through the LangChain Toolkit and requests all available actions along with their metadata like action name, description, input names, descriptions, etc.
- Runner prepares actions: The Runner downloads the source code for each plugin from their GitHub repositories and caches it locally for later use. After downloading, the Runner takes all available actions of these plugins and sends their info back to the OpenGPT.
- OpenGPT calls action: The OpenGPT uses the actions’ metadata to identify a suitable action and its input parameters based on the user's prompt. When the action is identified, and the OpenGPT decides to execute it, the OpenGPT sends a request to the Runner.
- Runner runs action: The Runner loads the plugin's source code from the cache, finds the action, and runs it with the provided parameters. When the result is ready, the Runner returns it to the OpenGPT.
- OpenGPT uses the result: OpenGPT then uses these results to finish its task. It continues the process until the user request is completed. This may include calling multiple actions, as seen in the demo.
Set up your own OpenGPT with Connery actions
To configure your own OpenGPT and actions, perform the following steps:
- Set up the Connery Runner using the Quickstart guide.
- Install plugins with the actions you want to use in your agent.
- Fork the OpenGPTs repo and configure it as specified in the README.
- Specify the
CONNERY_RUNNER_URLandCONNERY_RUNNER_API_KEYenvironment variables in the.envfile of the OpenGPTs to connect it to your Connery Runner.
💡
If you want to use Connery actions in your own apps and agents, you can use our LangChain Toolkit for Python and JS.
Next Steps
Currently, we are building out the features mentioned above. We would love to hear your feedback to prioritize the most important ones for the community. Please let us know what you think in our discussions board on GitHub.
Besides building out the necessary features, we plan to offer a managed service on top of the open-sourced Runner. Our goal is to simplify the integration process and help using actions much faster.
Connery plugins and their actions are individual GitHub repositories. This makes sharing and reuse very easy. With this, we envision a growing decentralized open-source plugin ecosystem, giving developers the freedom to innovate and collaborate on plugins. The first community plugins are being built.
- 登录 发表评论