
category

The Quest for Specialization
When challenging a difficult problem, divide and conquer is often a valuable solution. Whether it be Henry Ford’s assembly lines, the way merge sort partitions arrays, or how society at large tends to have people who specialize in specific jobs, the list goes on and on!
Naturally, when people approached the task of teaching computers to reason, it made sense to divide up the tasks we had for the machine into component pieces — for example, one component for math, one component for science, one for language, etc.
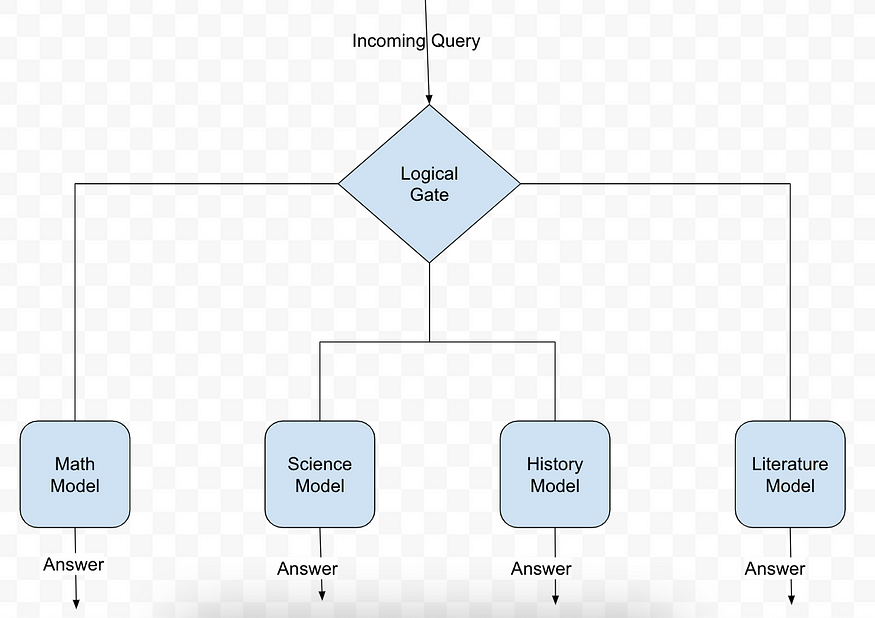
Nevertheless, this idea has not yet been successfully realized. It’s possible this is failing for the same reason that our brain doesn’t have nearly independent components: complex reasoning requires using many different parts in concert, not separately.
For the longest time, this idea lay somewhat dormant, until people stopped trying to create different components at the high level of mathematics or sciences, but rather at the lowest level for these neural networks — the tokens.
The “Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer” paper today goes in detail on how creating experts at the token level can be incredibly effective, both in reducing costs and increasing the quality of response.
Token-Level Mixture of Experts
Let’s begin with the idea of an ‘expert’ in this context. Experts are feed-forward neural networks. We then connect them to our main model via gates that will route the signal to specific experts. You can imagine our neural network thinks of these experts as simply more complex neurons within a layer.
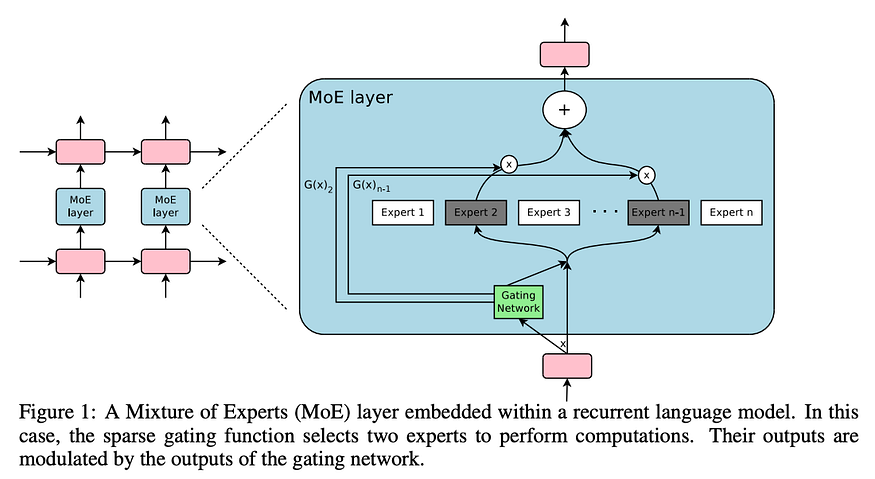
The problem with a naive implementation of the gates is that you have significantly increased the computational complexity of your neural network, potentially making your training costs enormous (especially for LLMs). So how do you get around this?
Conditional Computation & Sparsely Gated Mixture of Experts
The problem here is that neural networks will be required to calculate the value of a neuron so long as there is any signal going to it, so even the faintest amount of information sent to an expert triggers the whole expert network to be computed. The authors of the paper get around this by creating a function, G(x) that forces most low-value signals to compute to zero.
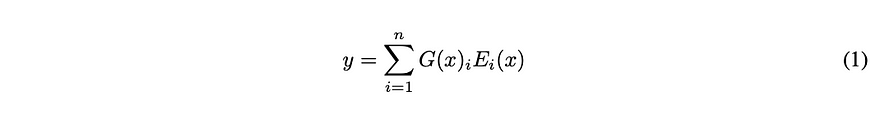
In the above equation, G(X) is our gating function, and E(x) is a function representing our expert. As any number times zero is zero, this logic prevents us from having to run our expert network when we are given a zero by our gating function. So how does the gating function determine which experts to compute?
Gating Function
The gating function itself is a rather ingenious way to only focus on the experts that you want. Let’s look at the equations below and then I’ll dive into how they all work.

Going from bottom to top, equation 5 is simply a step function. If the input is not within a certain range (here the top k elements of the list v), it will return — infinity, thus assuring a perfect 0 when plugged into Softmax. If the value is not -infinity, then a signal is passed through. This k parameter allows us to decide how many experts we’d like to hear from (k=1 would only route to 1 expert, k=2 would only route to 2 experts, etc.)
Equation 4 is how we determine what is in the list that we select the top k values from. We begin by multiplying the input to the gate (the signal x) by some weight Wg. This Wg is what will be trained in each successive round for the neural network. Note that the weight associated with each expert likely has a distinct value. Now to help prevent the same expert being chosen every single time, we add in some statistical noise via the second half of our equation. The authors propose distributing this noise along a normal distribution, but the key idea is to add in some randomness to help with expert selection.
Equation 3 simply combines the two equations and puts them into a SoftMax function so that we can be sure that -infinity gets us 0, and any other value will send a signal through to the expert.
The “sparse” part of the title comes from sparse matrices, or matrices where most of the values are zero, as this is what we effectively create with our gating function.
Optimizing the Loss Function to Balance Expert Usage
While our noise injection is valuable to reduce expert concentration, the authors found it was not enough to fully overcome the issue. To incentivize the model to use the experts nearly equally, they adjusted the loss function.
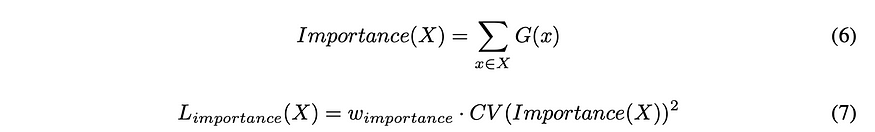
Equation 6 shows how they define importance in terms of the gate function — this makes sense as the gate function is ultimately the decider of which expert gets used. Importance here is the sum of all of the expert’s gate functions. They define their loss function as the coefficient of the variation of the set of Importance. Put simply, this means we are finding a value that represents just how much each expert is used, where a select few experts being used creates a big value and all of them being used creates a small value. The w importance is a hyperparameter that can aid the model to use more of the experts.

Getting Enough Training Data to the Experts
Another training challenge the paper calls out involves getting enough data to each of the experts. As a result of our gating function, the amount of data each expert sees is only a fraction of what a comparatively dense neural network would see. Put differently, because each expert will only see a part of the training data, it is effectively like we have taken our training data and hidden most of it from these experts. This makes us more susceptible to overfitting or underfitting.
This is not an easy problem to solve, so the authors suggest the following: leveraging data parallelism, leaning into convolutionality, and applying Mixture of Experts recurrently (rather than convolutionally). These are dense topics, so to prevent this blog post from getting too long I will go into these in later posts if there is interest.
Mixtral’s Implementation and Grok
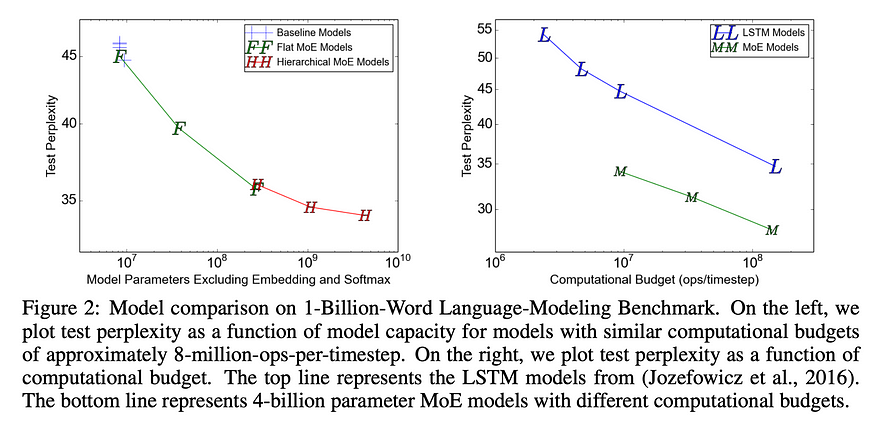
The “Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer” paper was published in 2017, the same year that the seminal Attention is All You Need paper came out. Just as it took some years before the architecture described in Self-Attention reached the main stream, it took a few years before we had any models that could successfully implement this Sparse architecture.
When Mistral released their Mixtral model in 2024, they showed the world just how powerful this setup can be. With the first production-grade LLM with this architecture, we can look at how it’s using its experts for further study. One of the most fascinating pieces here is we don’t really understand why specialization at the token level is so effective. If you look at the graph below for Mixtral, it is clear that with the exception of mathematics, no one expert is the go-to for any one high level subject.
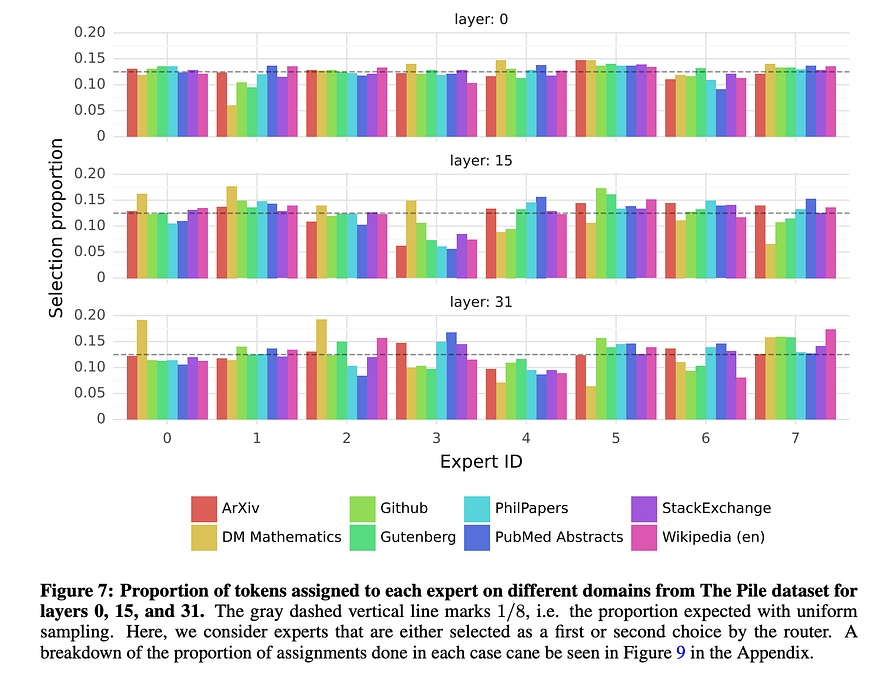
Consequently, we are left with an intriguing situation where this new architectural layer is a marked improvement yet nobody can explain exactly why this is so.
More major players have been following this architecture as well. Following the open release of Grok-1, we now know that Grok is a Sparse Mixture of Experts model, with 314 billion parameters. Clearly, this is an architecture people are willing to invest amounts of capital into and so will likely be a part of the next wave of foundation models. Major players in the space are moving quickly to push this architecture to new limits.
Closing Thoughts
The “Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer” paper ends suggesting experts created via a recurrent neural network are the natural next step, as recurrent neural networks tend to be even more powerful than feed-forward ones. If this is the case, then the next frontier of foundation models may not be networks with more parameters, but rather models with more complex experts.
In closing, I think this paper highlights two critical questions for future sparse mixture of experts studies to focus on. First, what scaling effects do we see now that we have added more complex nodes into our neural network? Second, does the complexity of an expert have good returns on cost? In other words, what scaling relationship do we see within the expert network? What are the limits on how complex it should be?
As this architecture is pushed to its limits, it will surely bring in many fantastic areas of research as we add in complexity for better results.
[1] N. Shazeer, et al., OUTRAGEOUSLY LARGE NEURAL NETWORKS:
THE SPARSELY-GATED MIXTURE-OF-EXPERTS LAYER (2017), arXiv
[2] A. Jiang, et al., Mixtral of Experts (2024), arXiv
[3] A. Vaswani, et al., Attention Is All You Need (2017), arXiv
[4] X AI, et al., Open Release of Grok-1 (2024), x ai website
- 登录 发表评论